Replication, caching and load-balancing are the simplest ways to deal with scaling systems, without partitioning/sharding data.
Caching is often done using tools such as Varnish, Squid, memcached, which store the result of common computations closer to the client. This has two benefits:
- a) The system does not recompute results, allowing more efficient use of the infrastructure.
- b) The data is moved closer to the client, reducing the number of hops taken to send results back to the client.
These techniques are hugely responsible for the success of web giants Google, Flickr, Facebook, Wikipedia and others.
The other common solution, often used in conjunction with a cache, is replication. Here, multiple copies of the entire data set or applications are distributed across the system. This allows many different resources to respond to simultaneous service requests that rely on the same computation base. However, while using this approach, it is important to consider several points.
- First, a strategy must be established to transparently distribute client requests to the replicas. This can be content-aware (specific requests are redirected to specific replicas) or content-blind.
- Next, the replicas should be monitored such that there is no imbalance (or hot spot) for the most frequently requested pages.
- Finally, maintaining consistency when writing across these replicas is another hard problem that we must learn how to deal with in the future. We will not address consistency in this week’s project.
temporal locality, which means that you assume that a target that is being searched for, may be requested multiple times in succession.
spatial locality -- say data about Target ID 2345 is requested for the first time. If it is safe to assume that #2345 is part of a gang of suspects, you may want to cache all IDs from 2345-2350. In this case, the first read may take longer than 12 ms, but future reads will take only 4 ms.
As a part of mastering debugging and monitoring on the cloud, you should be able to estimate these durations yourself.
Another thing to remember is that caching can be explicit and implicit, and can happen at multiple layers.
For e.g., in both situations above, you are explicitly caching the target’s records on the front-end. However, most data stores (DBs, file systems etc.) also employ a form of caching.
In this data center, the MSB stores the most recent 10,000 unique records per backend. Hence, if the example from the figure. was repeated several times, it would not really require 16 ms, even if there was no front-end caching. Instead, all future requests would take only 6 ms (the 10 ms fetch would take place only on the first read).
Project specific information
data format: targetID (number), first_name, last_name, encrypted data(text)
This data is served by the DCIs to individual client requests by the targetID.
- Therefore, a client (the load generator in our case) sends a targetID to the DCIs.
Each DC instance is able to cache around 10,000 records at any given time.
- this level of caching is insufficient when testing against our Load Generators.
The MSB system we deal with this week has **two replicas of a database** in the back end. This alleviates the chances of overwhelming a single instance during periods of heavy load.
Reference 1 Summary: [Analysis of Caching and Replication Strategies for Web Applications]
Web page caching, in which (fragments of) the HTML pages the application generates are cached to serve future requests.
Why Need?
- Content- delivery networks (CDNs)
- deploying edge servers around the Internet to locally cache Web pages and then deliver them to clients.
- By delivering pages from edge servers located close to the clients, CDNs reduce each request’s network latency.
- Work well if the same cached HTML page can answer many requests to a particular Web site.
- But with the growing drive toward personalized Web content, generated pages tend to be unique for each user, thereby reducing the benefits of page-caching techniques.
New Techniques
- New approaches for scalable Web application hosting can be classified broadly into four techniques:
- application code replication
- cache database records
- cache query results
- entire database replication
Instead of caching the dynamic pages generated by a central Web server, various techniques aim to replicate the means of generating pages over multiple edge servers.
- Often rely on the assumption that applications don’t require strict transactional semantics for their data accesses
- (as, for example, banking applications do).
- They typically provide “read-your-writes” consistency, which guarantees that when an application at an edge server performs an update, any subsequent reads from the same edge server will return that update’s effects (and possibly others).
Techniques to Scale Web Applications
- Edge Computing
- Data Replication
- For applications that exhibit poor locality, data-replication schemes perform better than CBC.
- Content-Aware Data Caching
- CAC didn’t perform as well as expected, mostly because the tested query workloads didn’t fully exploit CAC’s query containment features.
- Content-Blind Data Caching
- For applications whose query workload exhibited high locality, CBC performed the best.
Edge Computing
replicate the application code at multiple edge servers and keep the data centralized.
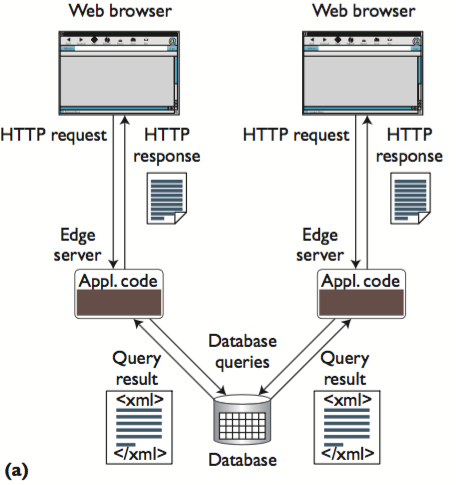
- This technique is the heart of the edge computing (EC) products at Akamai and ACDN.
- EC lets each edge server generate user-specific pages according to context, session, and information stored in the database, thereby spreading the computational load across multiple servers.
- However, this data centralization can also pose several problems.
- First, if the edge servers are located worldwide, each data access incurs wide-area network (WAN) latency;
- second, the central database quickly becomes a performance bottleneck because it needs to serve the entire system’s database requests.
- These properties restrict EC’s use to Web applications that require relatively few database accesses to generate content.
Data Replication
- The solution to EC’s database bottleneck problem is to place the data at each edge server so that generating a page requires only local computation and data access.
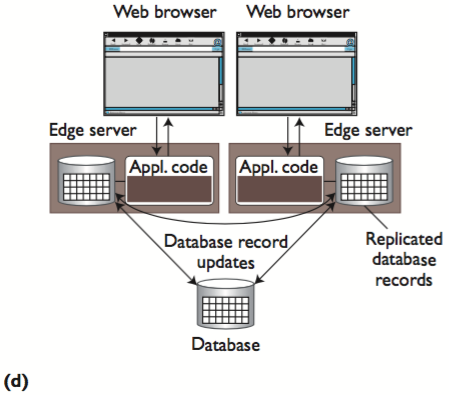
- Database replication (REPL) techniques can help here by maintaining identical copies of the database at multiple locations.
- However, in Web environments, database replicas are typically located across a WAN, whereas most REPL techniques assume the presence of a local-area network (LAN) between replicas.
- This can be a problem if a Web application generates many database updates.
- If this happens, each update must be propagated to all the other replicas to maintain the replicated data’s consistency, potentially introducing a huge network traffic and performance overhead.
In our study, we designed a simple replication middleware solution that serializes all updates at an origin server and propagates them to the edges in a lazy fashion. The edge servers answer each read query locally.
Content-Aware Data Caching
Instead of maintaining full copies of the database at each edge server, content-aware caching (CAC) systems cache database query results as the application code issues them.
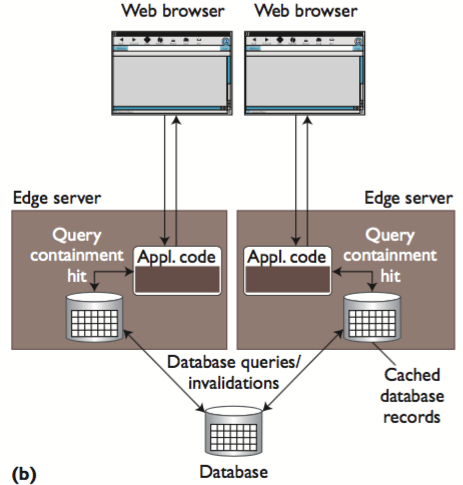
- each edge server maintains a partial copy of the database, and each time the application running at the edge issues a query, the edge-server database checks if it contains enough data locally to answer the query correctly.
- This process is called a query containment check.
- If the containment check result is positive, the edge server can execute the query locally; otherwise, it must be sent to the central database.
- In the latter case, the edge-server database inserts the result in its local database so that it can serve future identical requests locally.
- To insert cached tuples into the edge database, the caches create insert/update queries on the fly. Examples of CAC systems include DBCache and DBProxy.
CAC stores query results in a storage-efficient way — for example, the queries
“select * from items where price < 50”(Q1) and“select * from items where price < 20”(Q2) have overlapping results. By inserting both results into the same database, the overlapping records are stored only once.Another interesting feature of CAC is that once Q1’s results are stored, Q2 can execute locally, even though that particular query hasn’t been issued before.
- In this case, the query containment procedure recognizes that Q2’s results are contained in Q1’s results.
- CAC systems are beneficial when the application’s query workload has range queries or queries with multiple predicates (for example, to find items that satisfy
OR ).
- Typically, a query containment check is highly computationally expensive because it must check the new query with all previously cached queries. To reduce this cost, CAC systems exploit the fact that Web applications often consist of a fixed set of read and write query templates.
- A query template is a parameterized SQL query whose parameter values pass to the system at run-time.
- Use of query templates can vastly reduce the query containment’s search space because the edge-server database must check each incoming query only with a relatively small set of query templates.
- Using a template-based checking technique in our previous example, we might check Q1 and Q2 only with other cached instances of the template QT1,
“select * from items where price<?”, and not with instances of, for example, QT3,“select * from items where subject=?”. However, this method can also reduce the cache hit rate. - These systems often also use template-based mechanisms to ensure cache consistency. In CAC systems, the update queries always execute at the origin server (the central database server). When an edge server caches a query, it subscribes to receive invalidations of conflicting query templates. In our example, an update to change an item table’s price will conflict with QT1.
Content-Blind Data Caching
An alternative to CAC is content-blind query caching (CBC). In this case, edge servers don’t need to run a database at all. Instead, they store the results of remote database queries independently.
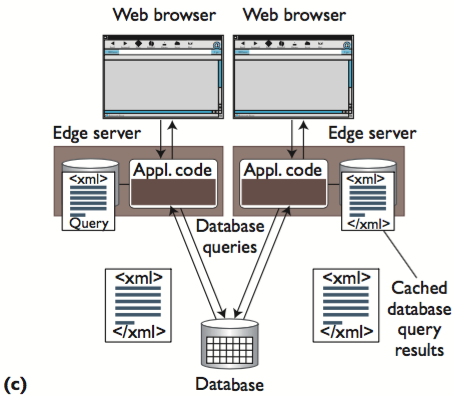
- CBC uses a method akin to template-based invalidation to maintain its cached results’ consistency.
- Because the query results aren’t merged together in CBC, caching the answers to the queries Q1 and Q2 defined earlier would lead to storing redundant information. Also, the cache will have a hit only if the application (running at the edge) issues the same exact query again at the same edge server.
- This can potentially lead to suboptimal usage of storage resources and lower cache hit rates, but it has some advantages.
- First, the process of checking if a query result is cached or not is trivial in CBC and incurs very little computational load.
- Second, by caching query results as result sets instead of database records, the CBC system can return results immediately.
- In contrast, CAC pays the price of database query execution, which can increase the load on edge servers.
- Finally, inserting a new element into the cache doesn’t require a query rewrite — rather, it merely stores objects.
Cache replacement is an important issue in any caching system because it determines which query results to cache and which ones to evict from the cache. An ideal cache replacement policy must take into account several metrics such as temporal locality, query cost, and the database’s update patterns.
Note that cache replacement in CBC is simple because each result is stored independently, and we can apply many popular replacement algorithms.
- However, because CAC merges multiple query results, its replacement policy should ensure that a query result’s removal doesn’t affect other cached queries’ results.