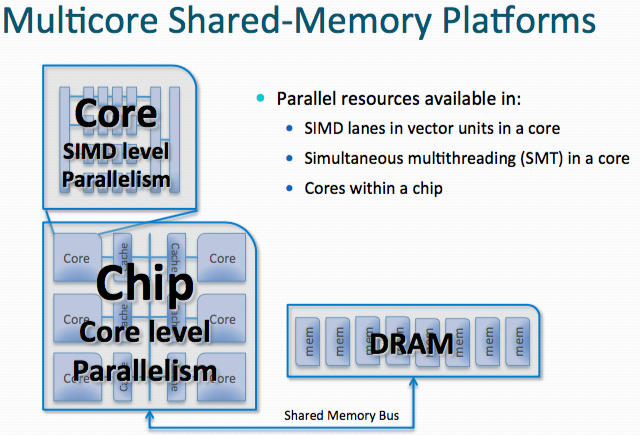
What are the exploitable levels of parallelism in a multicore processor?

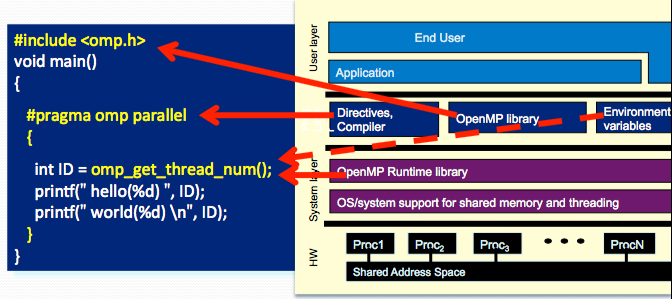
What is SPMD? And how to use OpenMP to do SPMD?
 SPMD: Single Program Multiple Data
SPMD: Single Program Multiple Data
- A parallel construct by itself creates an SPMD
- Each thread redundantly executes the same code.
- Programmer must explicitly specify what each thread must do differently
- The division of work is hard-coded in the program
Each thread executes a copy of the code within the structured block
What’s the difference between “critical” and “atomic”?
critical
- An OpenMP critical section is completely general - it can surround any arbitrary block of code.
You pay for that generality, however, by incurring significant overhead every time a thread enters and exits the critical section (on top of the inherent cost of serialization).
In addition, in OpenMP all unnamed critical sections are considered identical (if you prefer, there's only one lock for all unnamed critical sections), so that if one thread is in one [unnamed] critical section as above, no thread can enter any [unnamed] critical section.
Atomic
An atomic operation has much lower overhead. It relies on the hardware providing (say) an atomic increment operation; in that case there's no lock/unlock needed on entering/exiting the line of code, it just does the atomic increment which the hardware tells you can't be interfered with.
The upsides are that the overhead is much lower, and one thread being in an atomic operation doesn't block any (different) atomic operations about to happen.
The downsides are that you aren't guaranteed any particular set of atomic operations on any particular platform, and you could loose portability. The compiler should tell you if the particular atomic isn't supported, however.
How to reduce synchronization cost and avoid “false sharing”?
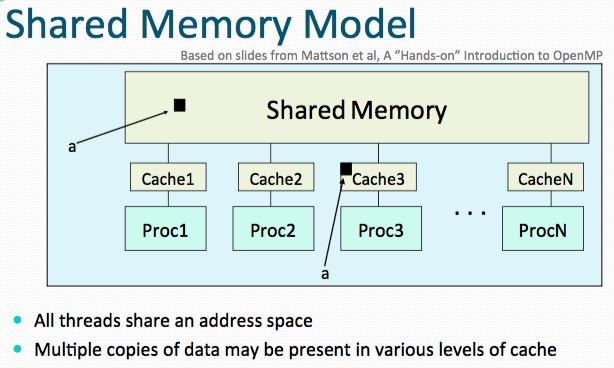
- Synchronization protocols are implemented in hardware to manage coherence between caches.
- But cache synchronization protocols induced severe performance penalties when no sharing is required
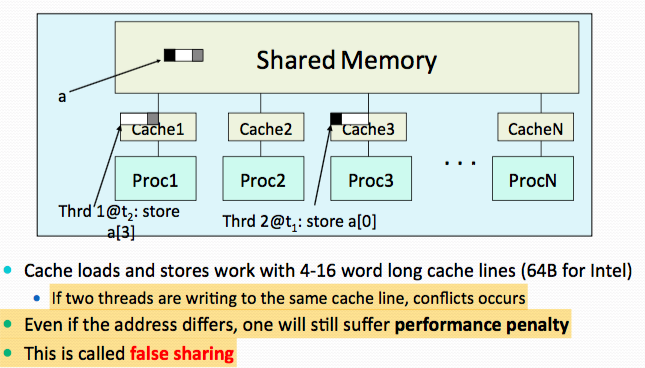
If independent data elements happen to sit on the same cache line, each update will cause the cache lines to “slosh back and forth” between threads. This is called “false sharing”.
Solution for false sharing:
- Be aware of the cache line sizes for a platform
- Avoid accessing the same cache line from different threads
- When updates to an item are frequent, work with local copies of data instead of an array indexed by the thread ID.
- Pad arrays so elements you use are on distinct cache lines.
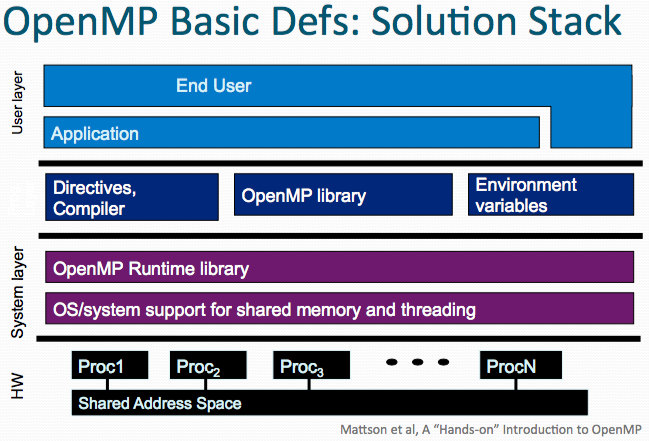
What are the scheduling, reduction, data sharing, and synchronization options for OpenMP?
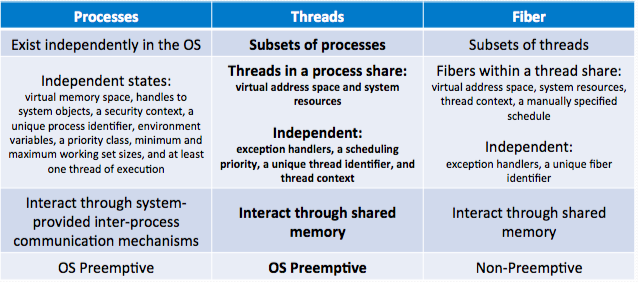
What is a thread?
- A thread of execution is a unit of processing scheduled by the OS
- Allows system resources to be shared efficiently.
Landscape of Thread Programming
- POSIX threads
- Defines a set of C programming language types, functions and constants.
- Manually expose and manage all concurrency with the API
- OpenMP
- Programmer hints at the concurrency
- Compiler manages the parallelism
- Intel Cilk Plus, Intel Thread Building Block (TBB)
- Programmer exposes the concurrency
- Runtime determines what is run in parallel
Work sharing
Split up pathways through the code between threads within a teamis calledwork sharingMethods:
- Loop construct
- Sections/section constructs
- Single construct
- Task construct