SIMD Programming
Notes from A practical guide to SSE SIMD with C++
SIMD Introduction
Some C/C++ compilers come with so called SSE intrinsics headers. These provide a set of C functions, which give almost direct access to the vectorized instructions and the needed packaged data types.
Unfortunately, coding with the C intrinsics is very inconvenient and results in unreadable code.
The second problem is that converting algorithms to effectively use even width four SIMD, as used by SSE, is at most times a very nontrivial task.
This can be solved with
C++ operator overloadingcapabilities without sacrificing performance.Additionally, each version of SSE is accessed by a different intrinsics header and the correct selection and detection should be handled by the wrapping C++ class.
The huge downside of SIMD is that the N paths can not be processed differently while in real life algorithms there will be need to process different data differently.
This kind of path divergence is handled in SSE either by multiple passes with different masks or by reverting to processing each path in scalar. If large proportion of an algorithm can be run without divergence then SSE can give benefit.
SIMD compared to other levels of parallel computing
In shared memory (thread) level parallelization different parallel paths can execute completely unique set of instructions. This makes for a much simpler parallel programming for example through an API like OpenMP.
This is also true for parallelization between different calculation units without shared memory. However, then usually communication has to be coded in manually through an interface like MPI.
Both of those are MIMD or multiple data and multiple instructions. Note that all of these parallel concepts can and should be utilized at the same time. For example MPI can be used to divide a job between computation units. Then OpenMP used to divide a part of the job between available threads. Finally vectorization can be utilized inside each thread.
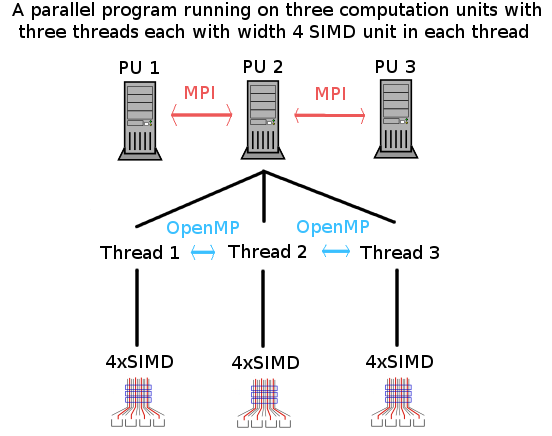
Effective use of SSE
SSE 2.0 up to the currently latest version 4.2 can process four single precision (32-bit) floating point numbers or two double precision (64-bit) floating point numbers in vectorized manner.
- If this is not enough precision then SSE will be of no use.
- Furthermore for double precision floating point data there is a realistic potential for speedup of less than 2x to begin with.
In most cases, only algorithms that are actually expensive enough or run enough times to be significant in total application run time should be vectorized, because of the additional work.
- Generally, of course, anything that be done in parallel mostly coherently with the same set of instructions is a candidate.
Data storage and byte boundary alignment
Intel's and AMD's processors will transfer data to and from memory into registers faster if the data is aligned to 16-byte boundaries.
While compiler will take care of this alignment when using the basic 128-bit type it means optimally data has to be stored in sets of four 32-bit floating point values in memory.
This is one more additional hurdle to deal with when using SSE. If data is not stored in this kind of fashion then more costly unaligned scalar memory moves are needed instead of packaged 128-bit aligned moves.
Intel optimization manual says: "Data must be 16-byte aligned when loading to and storing from the 128-bit XMM registers used by SSE/SSE2/SSE3/SSSE3. This must be done to avoid severe performance penalties."
Long code blocks and register usage
Effective SSE will minimize the amount of moving of data between memory subsystem and the CPU registers. The same is true of scalar code, however, the benefit is higher with SSE. (NOT REALLY UNDERSTAND)
Code blocks should be as long as possible, where the data is loaded into SSE registers only once and then results moved back into memory only once.
code blockis a pathway in code that has no boundaries that can no be eliminated by a compiler. An example of a boundary would be a function call that the compiler can not inline.
Storage to memory should be done when data is no longer needed in a code block.
While the compiler will be of great help for this optimization by inlining functions, algorithms and program structure have to be designed with this in mind.
SSE versions between 2.0 to 4.2 have total of eight 128-bit registers available in 32-bit mode and sixteen in 64-bit mode.
- The latter can hold total of 64 single precision floating point values in registers.
Data structures with SSE
The basic SSE 32-bit floating point data type is four floating point values in what is usually considered a horizontal structure.
$$m = f_1 f_2 f_3 f_4$$
- It is horizontal because most SSE instructions operate on data vertically.
- Note that this is a 128-bit continuous block of four 32-bit floats in memory. In code this will be called
vec4.
Possible structure:
Array of structures (AOS)
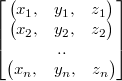
Structure of arrays (SOA)
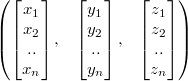
Example: 3-D Vectors:
- AOS:

- SOA:
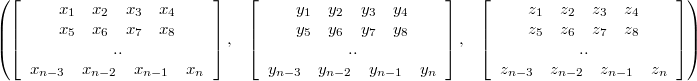
The difference between the two then is that depending on the task the other uses memory cache more efficiently.