Global Memory
- Global memory resides in device memory and device memory is accessed via 32-, 64-, or 128-byte memory transactions.
These memory transactions must be naturally aligned
- Only the 32-, 64-, or 128-byte segments of device memory that are aligned to their size (i.e. whose first address is a multiple of their size) can be read or written by memory transactions.
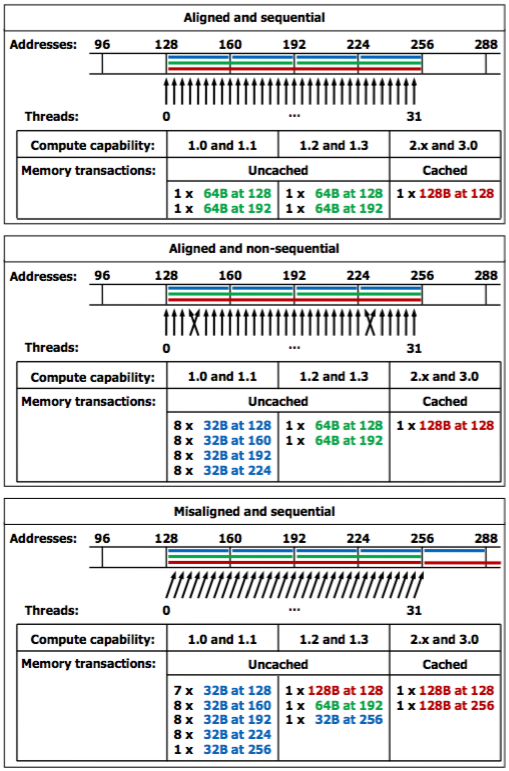
When a warp executes an instruction that accesses global memory, it coalesces the memory accesses of the threads within the warp into one or more of these memory transactions depending on the size of the word accessed by each thread and the distribution of the memory addresses across the threads.
- In general, the more transactions are necessary, the more unused words are transferred in addition to the words accessed by the threads, reducing the instruction throughput accordingly.
- For example, if a 32-byte memory transaction is generated for each thread’s 4-byte access, throughput is divided by 8.
How many transactions are necessary and how much throughput is ultimately affected varies with the compute capability of the device.
- For devices of compute capability 2.x and higher, the memory transactions are cached, so data locality is exploited to reduce impact on throughput.
To maximize global memory throughput, it is therefore important to maximize coalescing by:
- (1) Following the most optimal access patterns.
- (2) Using data types that meet the size and alignment requirement.
- (3) Padding data in some cases.
Global memory accesses for devices of compute capability 3.0 behave in the same way as for devices of compute capability 2.x
Optimal Access Pattern
Global memory accesses are cached. Using the
–dlcmcompilation flag, they can be configured at compile time to be cached in both L1 and L2-Xptxas -dlcm=ca(this is the default setting) or in L2 only-Xptxas -dlcm=cg.A cache line is 128 bytes and maps to a 128-byte aligned segment in device memory.
Memory accesses that are cached in both L1 and L2 are serviced with 128-byte memory transactions
whereas memory accesses that are cached in L2 only are serviced with 32-byte memory transactions.
- Caching in L2 only can therefore reduce over-fetch, for example, in the case of scattered memory accesses.
If the size of the words accessed by each thread is more than 4 bytes, a memory request by a warp is first split into separate 128-byte memory requests that are issued independently:
- Two memory requests, one for each half-warp, if the size is 8 bytes,
- Four memory requests, one for each quarter-warp, if the size is 16 bytes.
Each memory request is then broken down into cache line requests that are issued independently.
A cache line request is serviced at the throughput of L1 or L2 cache in case of a cache hit, or at the throughput of device memory, otherwise.
Note that threads can access any words in any order, including the same words. If a non-atomic instruction executed by a warp writes to the same location in global memory for more than one of the threads of the warp, only one thread performs a write and which thread does it is undefined.