OpenMP
An API for Writing Multithreaded Applications
- A set of compiler directives and library routines for parallel application programmers
Common API
int omp_get_num_threads(); //Number of threads in the team
int omp_get_thread_num(); //Thread ID or rank
double omp_get_wtime();//Time in Seconds since a fixed point in the past
OpenMP core syntax
- Most of the constructs in OpenMP are compiler directives.
#pragma omp construct [clause [clause] ] //Example #pragma omp parallel num_threads(4) - Function prototypes and types in the file:
#include <omp.h> - Most OpenMP* constructs apply to a
structured block.- Structured block: a block of one or more statements with one point of entry at the top and one point of exit at the bottom.
- It’s OK to have an exit() within the structured block.
How do threads interact?
- OpenMP is a multi-threading, shared address model.
- Threads communicate by
sharing variables. - Unintended sharing of data causes race conditions:
- Threads communicate by
race condition:
when the program’s outcome changes as the threads are scheduled differently.
- To control race conditions:
- Use
synchronizationto protect data conflicts. - Synchronization is expensive so: Change
how data is accessedto minimize the need for synchronization.
- Use
Thread Creation: Parallel Regions
- You create threads in OpenMP* with the
parallel construct. - Each thread executes the same code redundantly.

Synchronization
Synchronization is used to impose order constraints and to protect access to shared data
- High level synchronization:
- critical
- atomic
- barrier
- ordered
- Low level synchronization
- flush
- locks (both simple and nested)
Synchronization: critical
Mutual exclusion: Only one thread at a time can enter a critical region.
float res; #pragma omp parallel{ float B; int i, id, nthrds; id = omp_get_thread_num(); nthrds = omp_get_num_threads(); for (i = id; i < niters; i+nthrds) { B = big_job(i); #pragma omp critical consume (B, res); } }Synchronization: Atomic
- Atomic provides mutual exclusion but only applies to the update of a memory location
Synchronization: Barrier
- Barrier: Each thread waits until all threads arrive.

Synchronization: ordered
- The ordered region executes in the sequential order.
Work sharing
Split up pathways through the code between threads within a teamis calledwork sharingMethods:
- Loop construct
- Sections/section constructs
- Single construct
- Task construct
Work Sharing with Loops
Basic approach
- Find compute intensive loops
- Make the loop iterations independent .. So they can safely execute in any order without loop-carried dependencies
- Place the appropriate OpenMP directive and test
- Note: loop index “i” is
privateby default
Work Sharing with Master Construct
The master construct denotes a structured block that is only executed by the master thread.
- The other threads just skip it (no synchronization is implied).
#pragma omp parallel { do_many_things(); #pragma omp master { exchange_boundaries(); } #pragma omp barrier do_many_other_things(); }Work Sharing with Single Construct
The single construct denotes a block of code that is executed by only one thread (not necessarily the master thread).- A barrier is implied at the end of the single block (can remove the barrier with a nowait clause).
#pragma omp parallel { do_many_things(); #pragma omp single { exchange_boundaries(); } do_many_other_things(); }Reduction
OpenMP reduction clause:reduction (op : list)- We are combining values into a single accumulation variable (ave) ... there is a true dependence between loop iterations that can’t be trivially removed
- Support for reduction operations is included in most parallel programming environments.
- Inside a parallel or a work-sharing construct:
- A local copy of each
listvariable is made and initialized depending on theop(e.g. 0 for “+”).- Compiler finds standard reduction expressions containing
opand uses them to update the local copy.- Local copies are reduced into a single value and combined with the original global value.
- The variables in “list” must be shared in the enclosing parallel region.
Reduction operands/initial-values

Data environment: Default storage attributes
- Shared Memory programming model:
- Most variables are shared by default
- Global variables are SHARED among threads
- C: File scope variables, static. dynamically allocated memory (ALLOCATE, malloc, new)
- But not everything is shared...
- functions(C) called from parallel regions are PRIVATE
- Automatic variables within a statement block are PRIVATE.

Changing storage attributes One can selectively change storage attributes for constructs using the following clauses*
SHAREDPRIVATE: private(var) creates a new local copy of var for each thread.FIRSTPRIVATE: Initializes each private copy with the corresponding value from the master thread.LASTPRIVATE: Lastprivate passes the value of a private from the last iteration to a global variable.- All the clauses on this page All the clauses on this page apply to the OpenMP construct apply to the OpenMP construct, NOT to the entire region.
Data Sharing: Default Clause
- the default storage attribute is DEFAULT(SHARED) (so no need to use it) Exception: #pragma omp task
- DEFAULT(NONE): no default for variables in static extent. Must list storage attribute for each variable in static extent. Good programming practice!
Sections worksharing Construct
- The Sections worksharing construct gives a different structured block to each thread.

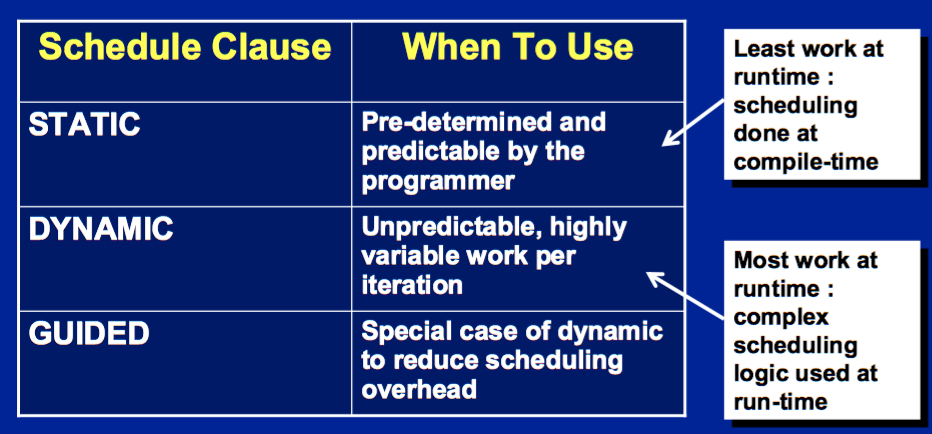
Loop worksharing constructs: The schedule clause
schedule(static [,chunk])- Deal-out blocks of iterations of size “chunk” to each thread.
schedule(dynamic[,chunk])- Each thread grabs “chunk” iterations off a queue until all iterations have been handled.
schedule(guided[,chunk])- Threads dynamically grab blocks of iterations.
- The size of the block starts large and shrinks down to size “chunk” as the calculation proceeds.
schedule(runtime)- Schedule and chunk size taken from the OMP_SCHEDULE environment variable (or the runtime library for OpenMP 3.0)
- Schedule and chunk size taken from the OMP_SCHEDULE environment variable (or the runtime library for OpenMP 3.0)