Basic Underscene of Common Usage
When you create the commit by running git commit ...
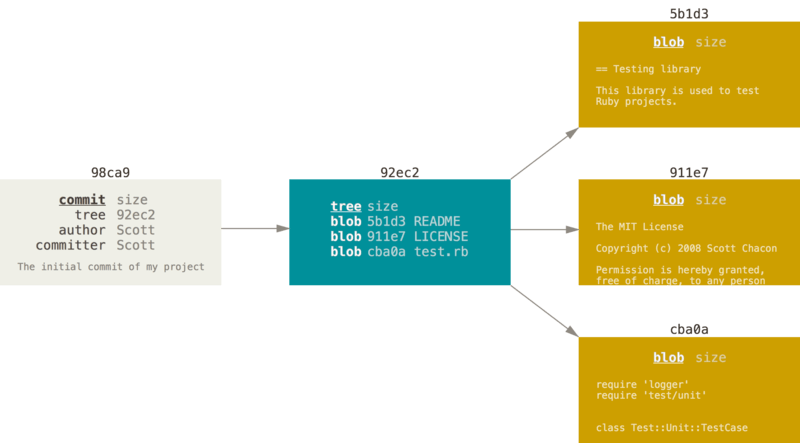
Your Git repository now contains five objects: one blob for the contents of each of your three files, one tree that lists the contents of the directory and specifies which file names are stored as which blobs, and one commit with the pointer to that root tree and all the commit metadata.
- Git checksums each subdirectory (in this case, just the root project directory)
- stores those tree objects in the Git repository.
- Git then creates a commit object that has the metadata and a pointer to the root project tree so it can re-create that snapshot when needed.
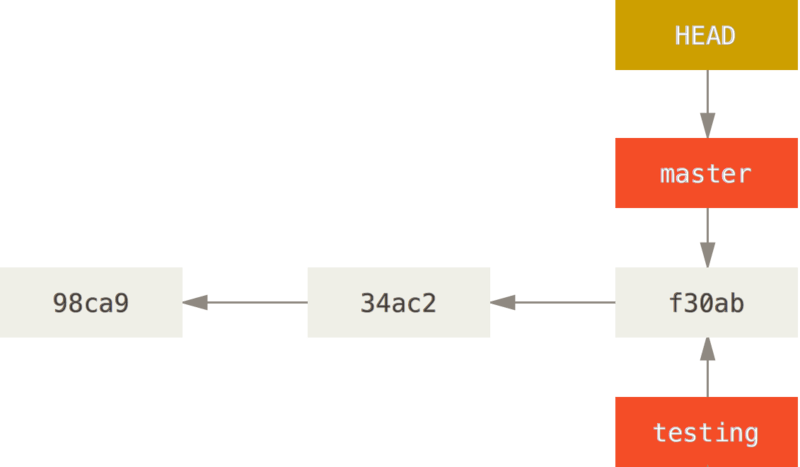
Creating a New Branch testing
creates a new pointer to the same commit you’re currently on.
- a branch in Git is in actuality a simple file that contains the 40 character SHA-1 checksum of the commit it points to, branches are cheap to create and destroy
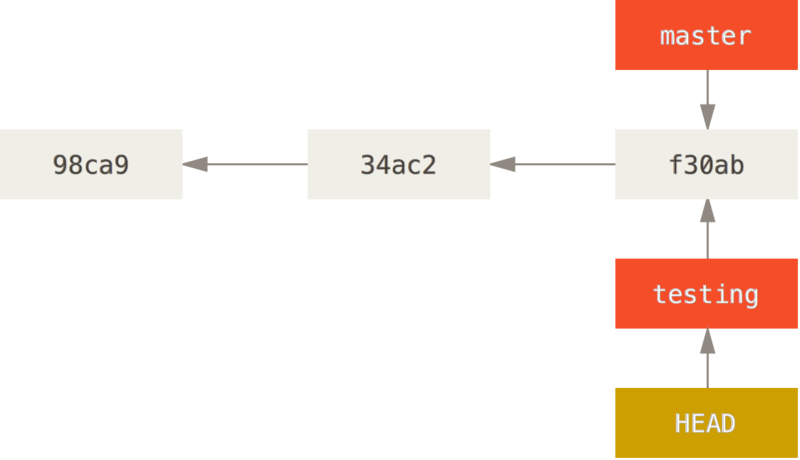
Switching to Branche testing
moves
HEADto point to thetestingbranch.
Working with remote
1. Local and remote work can diverge
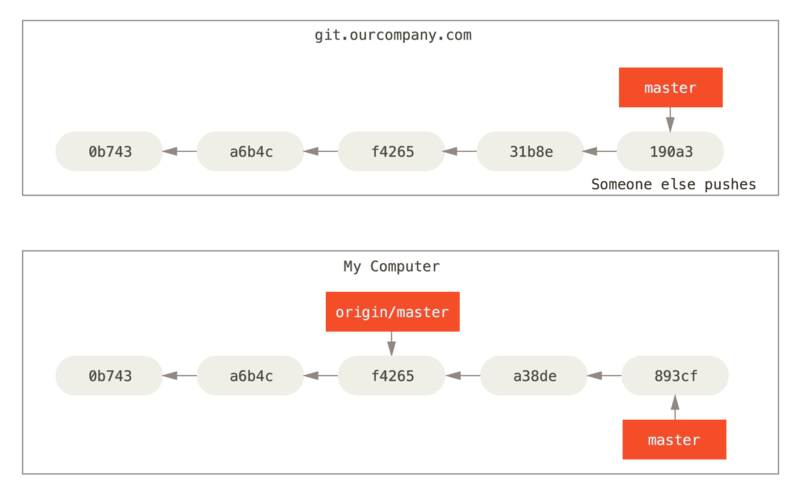
2. After git fetch [origin]
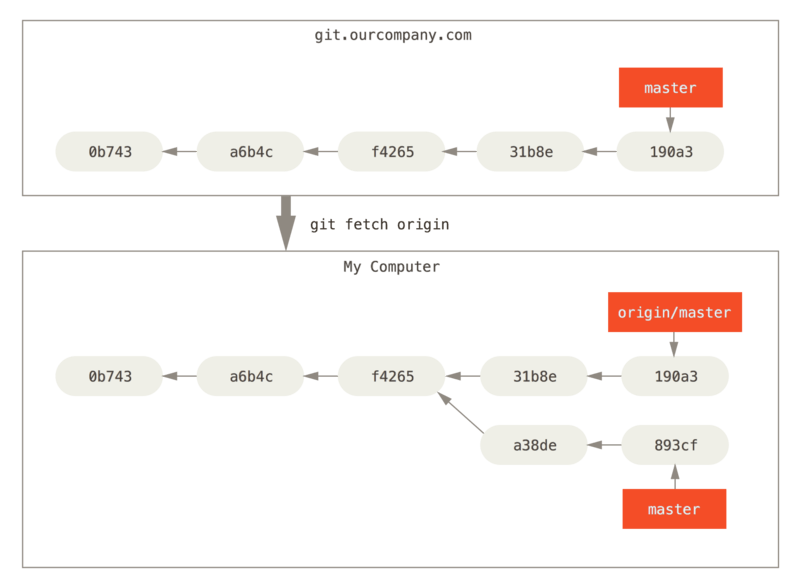
git fetch [origin]looks up which server “origin” is, fetches any data from it that you don’t yet have, and updates your local database, moving your origin/master pointer to its new, more up-to-date position.
3. If fetch from a different branch (teamone) from remote?
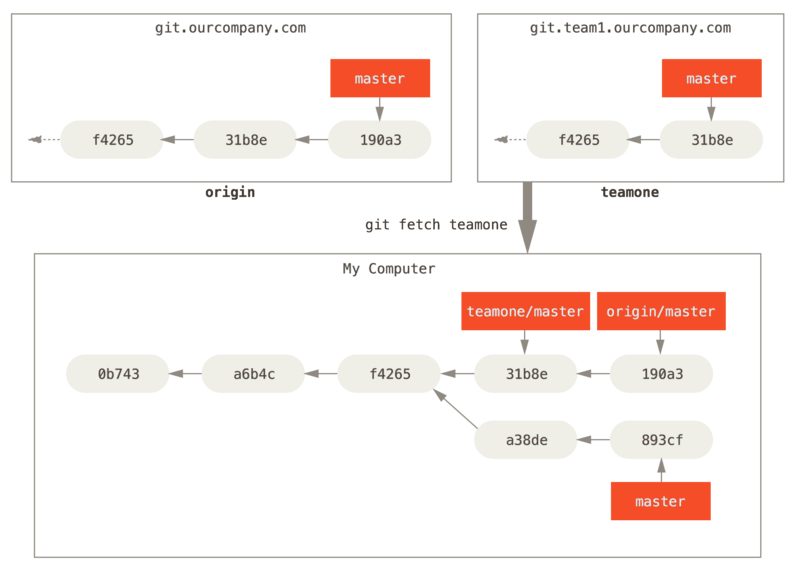
git fetch teamoneto fetch everything the remote teamone server has that you don’t have yet. Because that server has a subset of the data your origin server has right now, Git fetches no data but sets a remote-tracking branch called teamone/master to point to the commit that teamone has as its master branch.
Basic Rebase
- It works by going to the common ancestor of the two branches.
- rebasing makes for a cleaner history.
1.Before rebasing
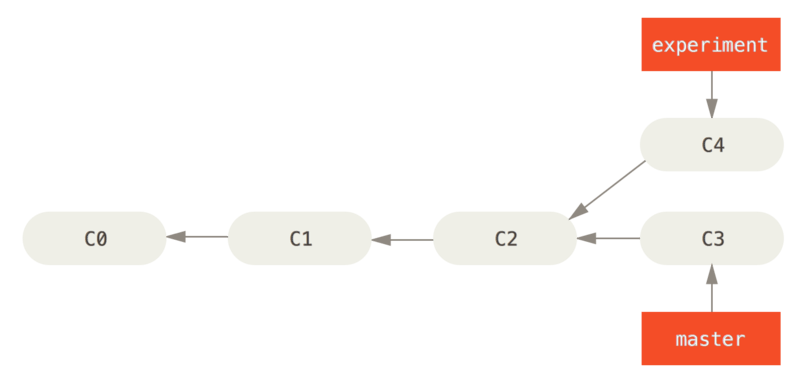
$ git checkout experiment
$ git rebase master
2. After rebasing
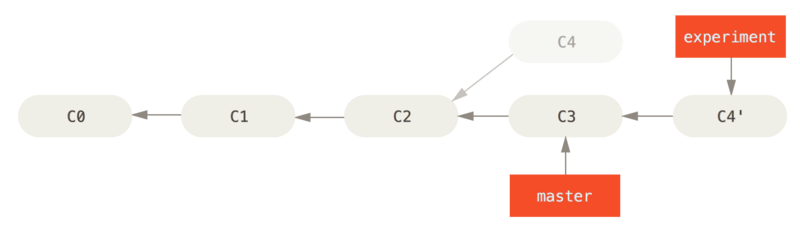
$ git checkout master
$ git merge experiment
3. Merge master back
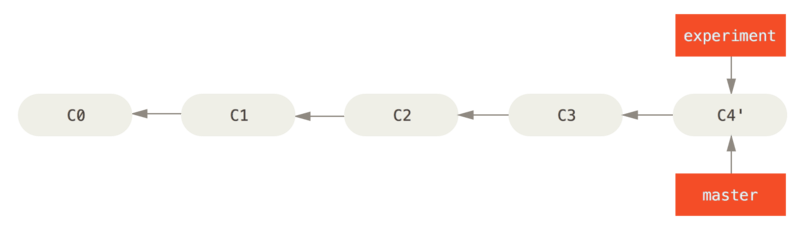
More complicated rebasing
You can also have your rebase replay on something other than the rebase target branch. Suppose you decide that you want to merge your client-side changes into your mainline for a release, but you want to hold off on the server-side changes until it’s tested further.
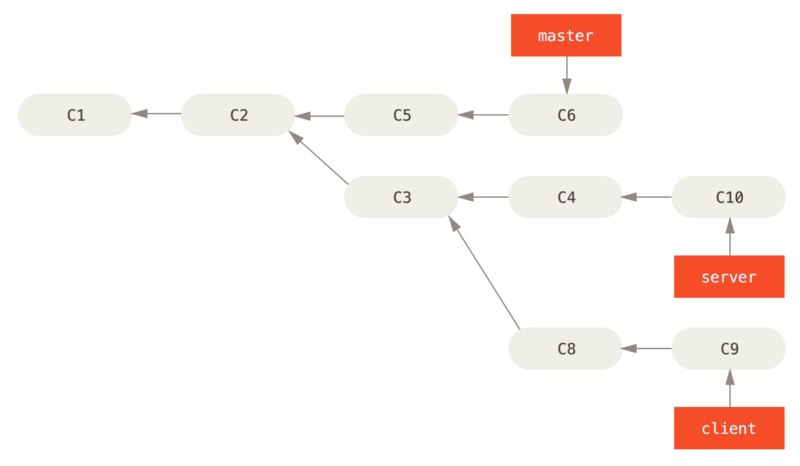
- You can take the changes on client that aren’t on server (C8 and C9) and replay them on your master branch by using the
--ontooption ofgit rebasegit rebase --onto master server client - “Check out the client branch, figure out the patches from the common ancestor of the client and server branches, and then replay them onto master.”
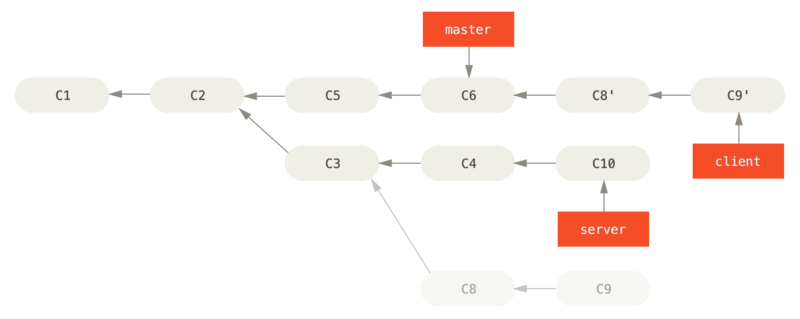
fast-forward master
$ git checkout master $ git merge client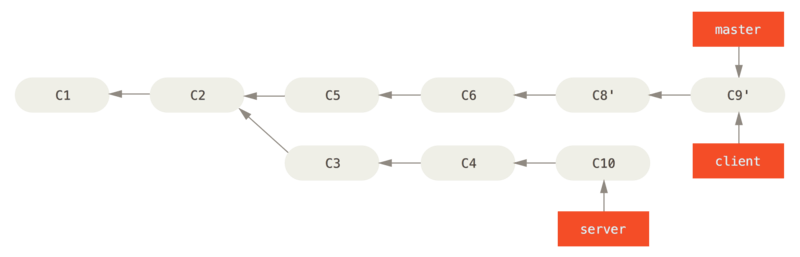
rebase server onto master
$ git rebase master server
again, fast-forward master then delete unused branch
$ git checkout master $ git merge server $ git branch -d client $ git branch -d server
Why "Do not rebase commits that exist outside your repository"?
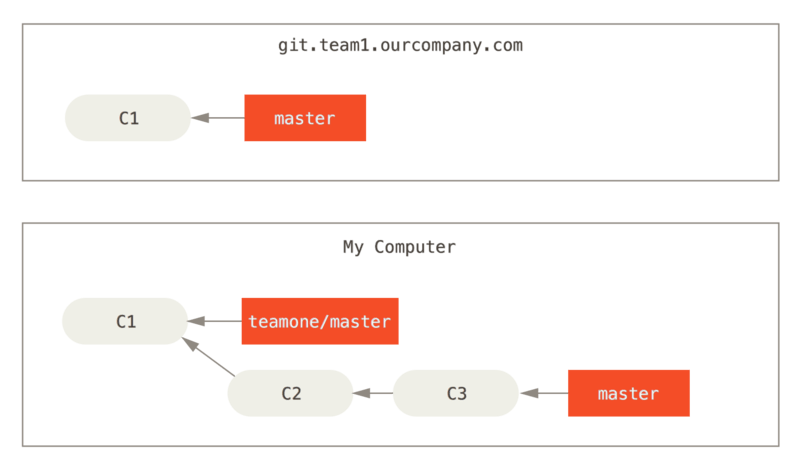
1. You clone a repository, and base some work on it (C2, C3)
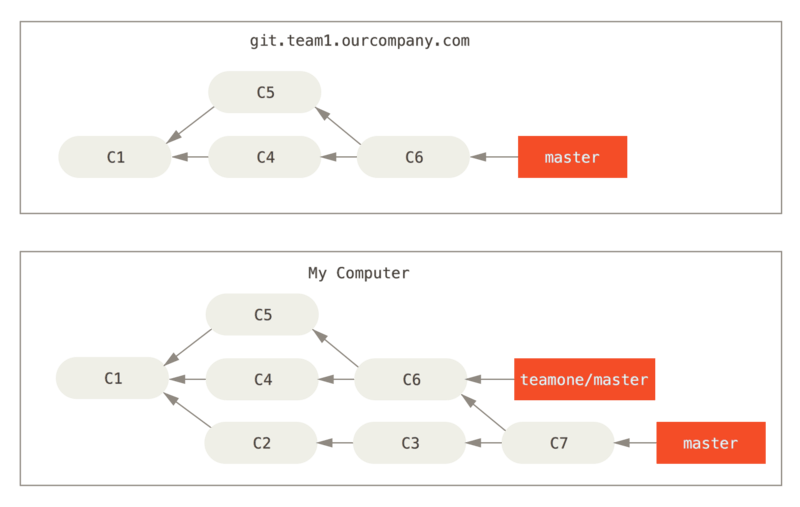
2. Someone push the code on to remote (C4, C5, C6), then u fetch from remote and merge to your C3, which becomes C7
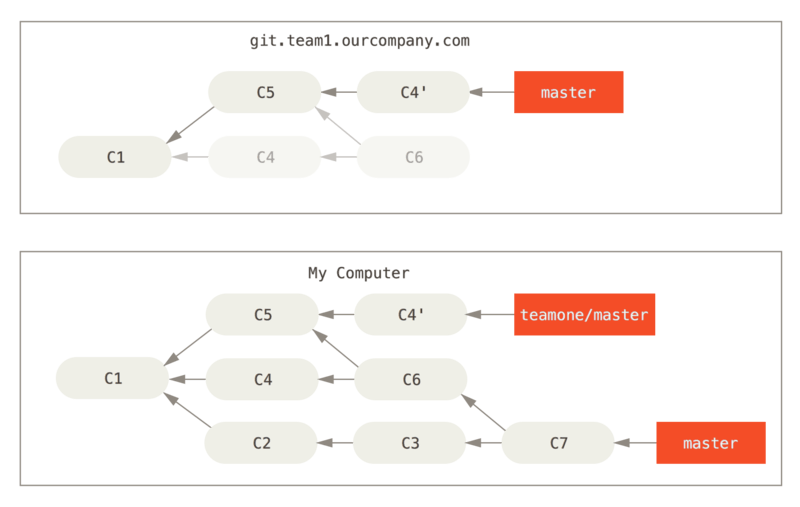
3. Someone (force) pushes rebased commits, abandoning commits you’ve based your work on
4. Then u try to fetch from the remote, which becomes C8
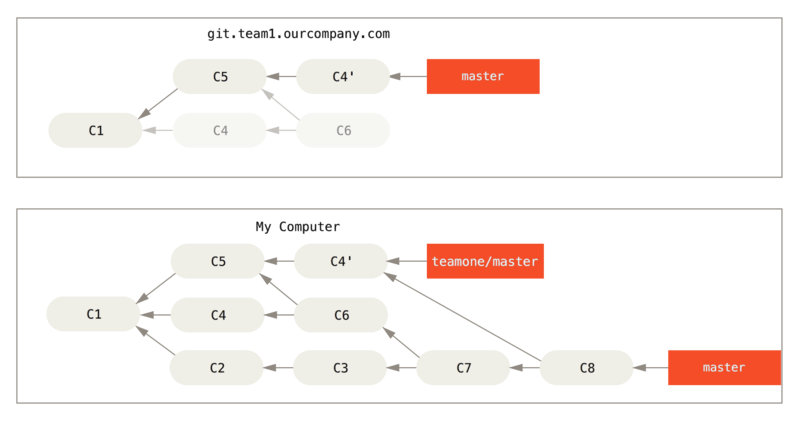
Problems: when u push back to the remote, the missing C4 C6 on remote is back...
So if step 3 really happens, how to resolve?
4.2 Using git rebase teamone/master instead of git fetch/pull
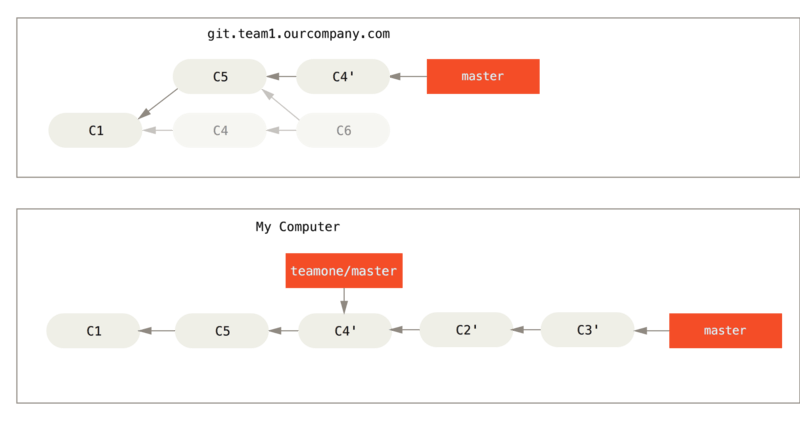
- This only works if C4 and C4' that your partner made are almost exactly the same patch. Otherwise the rebase won’t be able to tell that it’s a duplicate and will add another C4-like patch (which will probably fail to apply cleanly, since the changes would already be at least somewhat there).