What’s the Difference between Multicore and Manycore?
Fundamentally different design philosophy
 Multicore
Multicore
- Yoke of oxen
- Optimized for reducing execution latency of a few threads
- Sophisticated instruction controls, large caches
- Each core optimized for executing a single thread
Manycore
- Flock of chickens
- Assumes 1000-way concurrency readily available in applications
- More resources dedicated to compute Cores optimized for aggregate throughput, deemphasizing individual performance
When does using a GPU make sense?
- Applications with a lot of concurrency
- 1000-way,fine-grained concurrency
- Some memory intensive applications
- Aggregate memory bandwidth is higher on the GPU
- Advantage diminishes when task granularity becomes to large to fit in shared memory
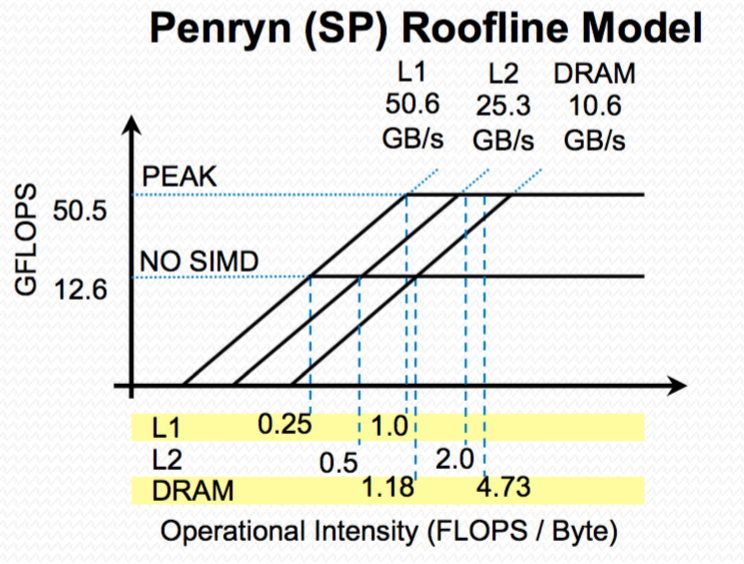
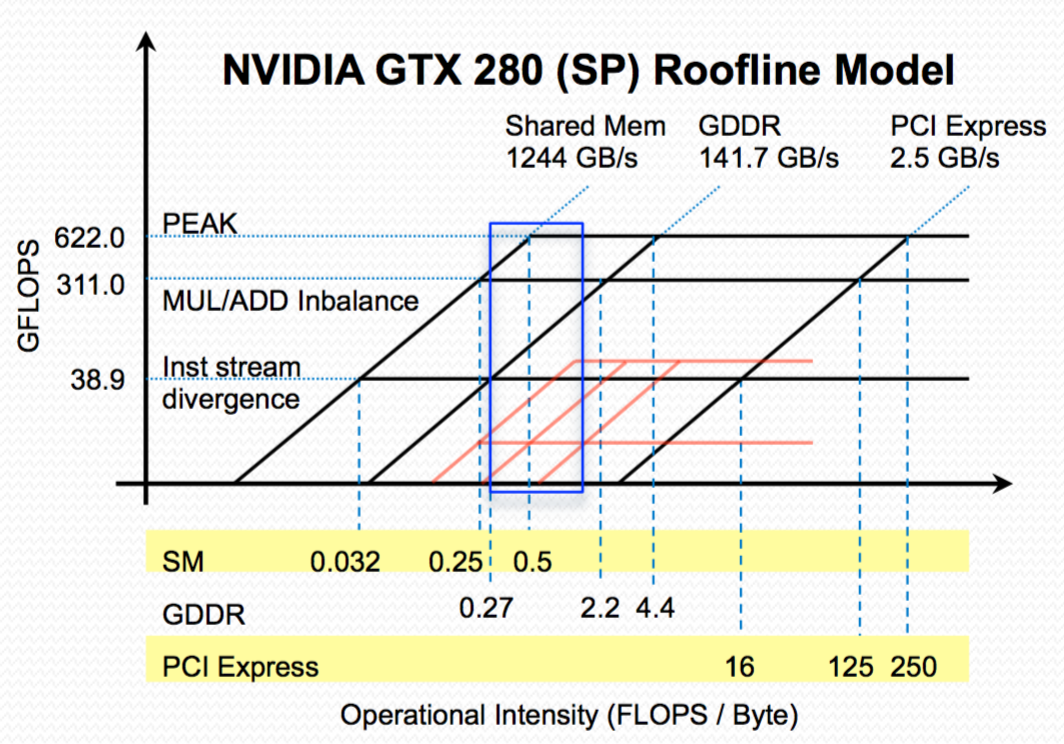
What is the memory hierarchy inversion? And why is it there?
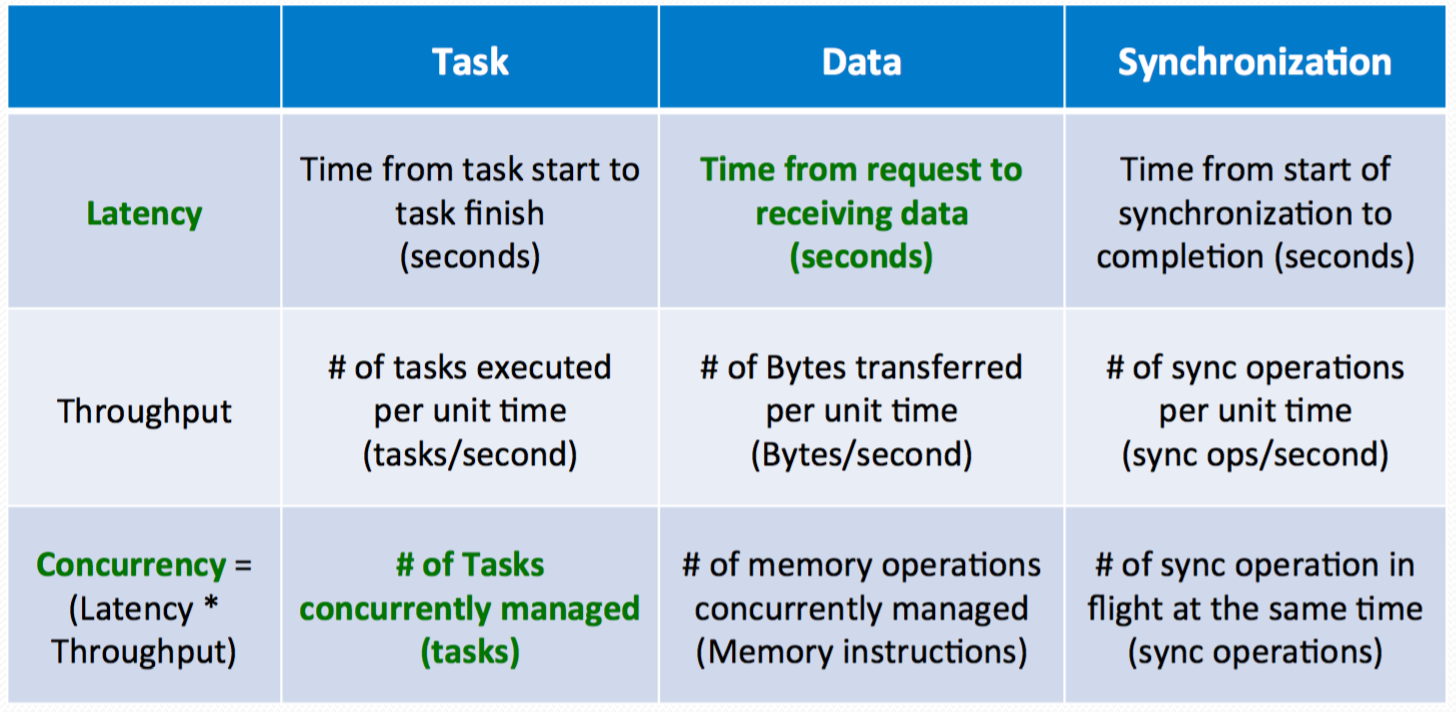
- Manycore's philosophy: maximize throughput
- Factors: task, data, synchronization
- Difficulty: the latency of getting data
- What GPU tries to do: maximize concurrency so that the total # of tasks concurrently managed can be maximized, such that total throughtput of processor can be maximized
What is the memory wall?
Increasing gap between fetching data from memory and processing data on processor
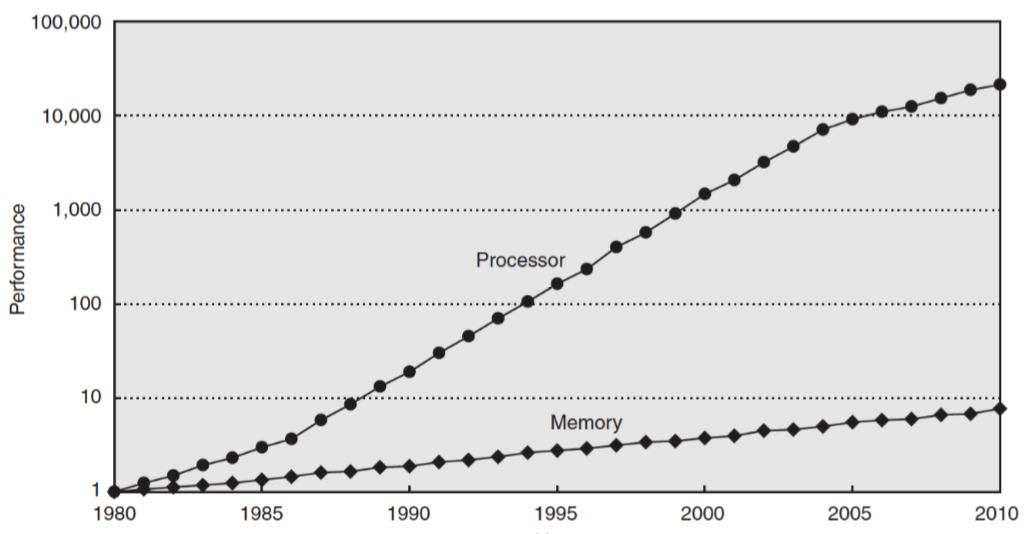
How to get around memory wall?
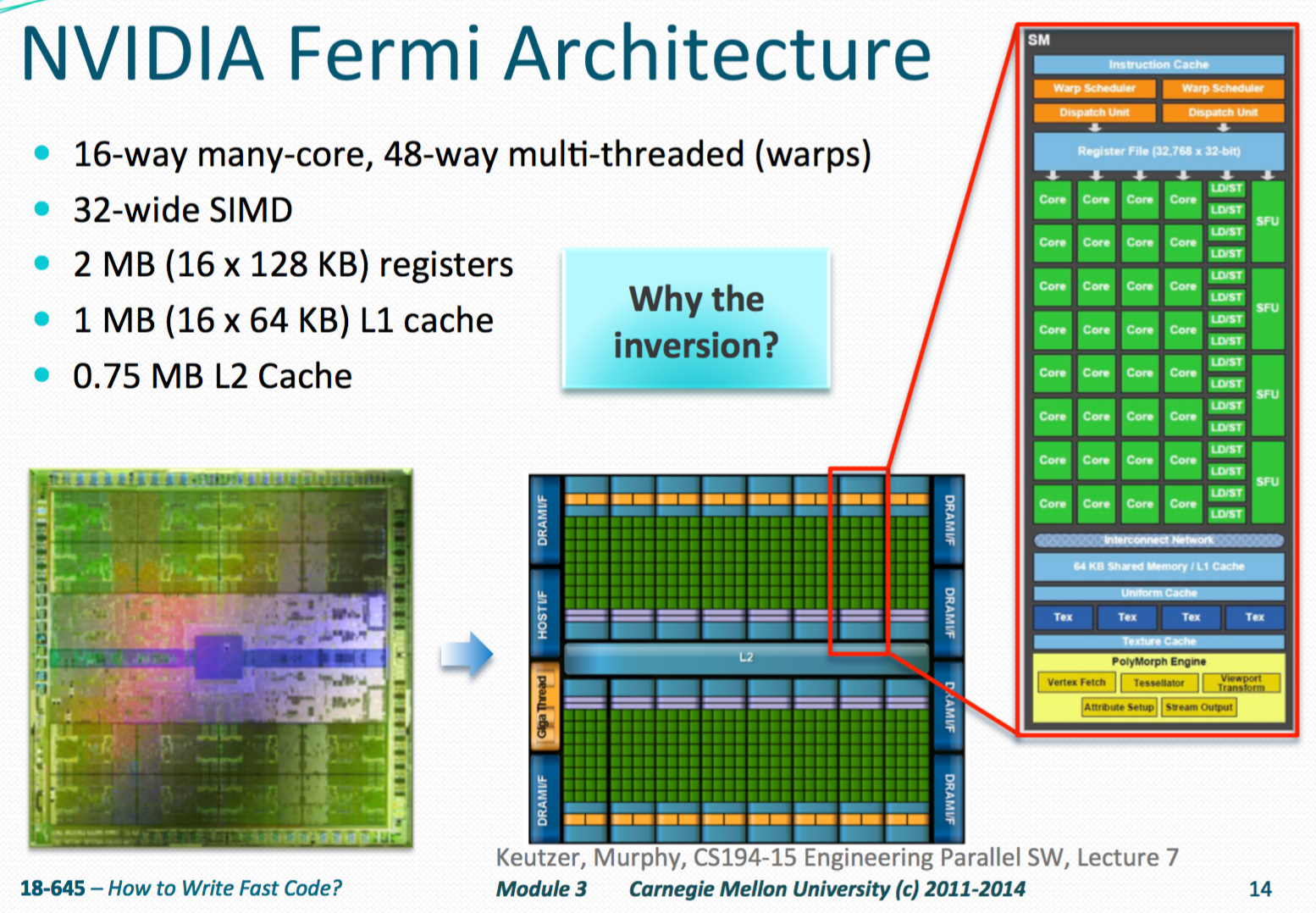
- Manycore Processors try to utilize application concurrency to hide memory latency
- Each Fermi core can maintain 48 warps of architectural context
- core = streaming multiprocessor
- Each warp manages a 32-wide SIMD vector worth of computation
- With ~20 registers for each thread:
- 4 (Bytes/register) x 20 (Registers) x 32 (SIMD lanes) x 48 (Warps) $\rightarrow$ 128KB per core $\rightarrow$ x 16 (core) = 2MB total of register files
Why warps?
- Software abstraction to hide an extra level of architectural complexity
- A 128KB register file is a large memory
- It takes more than one clock cycle to retrieve information
- Hardware provide 16-wide physical SIMD units, half-pump register files
- Provide half the operand per clock cycle,then the other half the following cycle
- To simplify the programming model: Assume we are only working with 32-wide SIMD unit,where each 32-bit instruction has a bit more latency
How do we deal with GPUs of different sizes?
Thread block abstraction
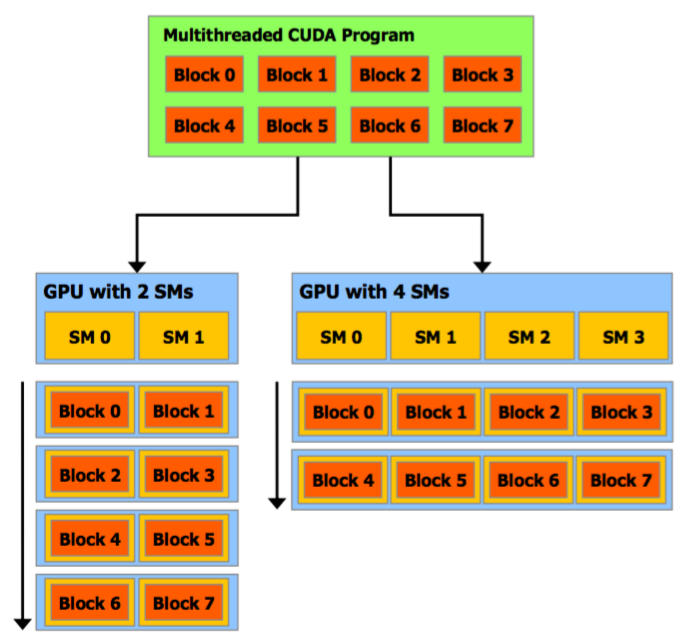
- CUDA provides an abstraction for concurrency to be fully exposed
What are the implications of the thread block abstraction?
- Computation is grouped into blocks of independent, concurrently executable work
- The HW/Runtime makes the decision to selectively sequentialize the execution as necessary
- One can often achieve higher performance to have less threads/block,but multiple blocks concurrently running on the same core
How do threads communicate with each other?
- Manycore processors provide memory local to each core
- Computations in SIMD-lanes in the same core can communicate via memory read/write
- Two types of memory:
- Programmer-managed scratch pad memory
- HW-managed L1 cache
- Two types of memory:
- For NVIDIA Fermi architecture, you get 64KB per core with two configurations
- 48KB scratch pad (Shared Memory),16kBL1cache
- 16KB scratch pad (SharedMemory),48 kB L1 cache
What is the caveat in synchronizing threads __syncthreads() in a thread block?
- waits until all threads in the thread block have reached this point and all global and shared memory accesses made by these threads prior to
__syncthreads()are visible to all threads in the block - used to coordinate communication between the threads of the same block
- Keep
__syncthreads()outside any condition!!
Misc: SIMT
- Threads are the computation performed in each SIMD lane in a core
CUDA provides a SIMT programming abstraction to assist users
SIMT: Single Instruction Multiple Threads
- A single instruction controls multiple processing element
- Different from SIMD
- SIMD exposes the SIMD width to the programmer
- SIMT abstract the #threads in a thread block as a user-specified parameter
- SIMT enables programmers to write thread-level parallel code for independent, scalar threads
- Data-parallel code for coordinated threads
- For functional correctness, programmers can ignore SIMT behavior
- For performance, programmers can tune applications with SIMT in mind
- A single instruction controls multiple processing element
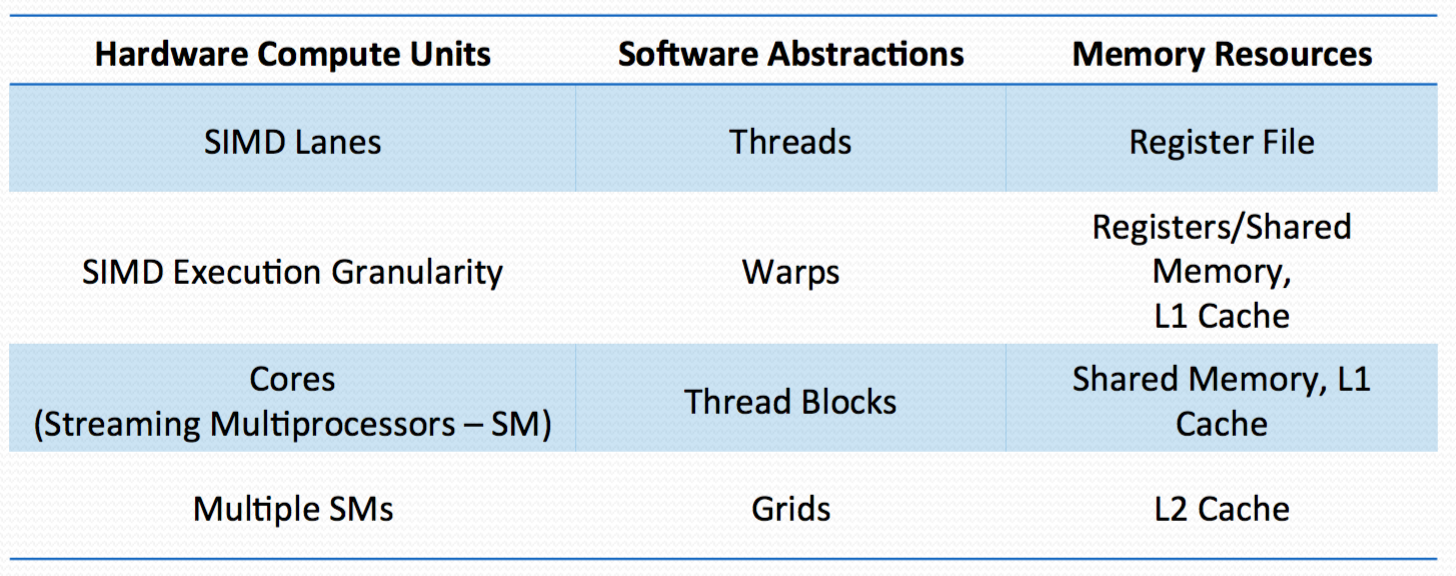
Misc: Hardware and Software Mental Models
Misc: why not just put all my work in one thread block?
- A many core processor has more than one core
- If one uses only one core, one is not fully utilizing available HW
- Hardware must maintain the context of all threads a thread block
- There is a limited amount of resources on-chip
- In Fermi
- 48 warps of context are maintained per core
- Each thread block can have up to 1024 threads
Misc: Compute capability
- The compute capability of a device is defined by a major revision number and a minor revision number.
- Devices with the same major revision number are of the same core architecture.
- The major revision number is 3 for devices based on the Kepler architecture, 2 for devices based on the Fermi architecture, and 1 for devices based on the Tesla architecture.
- The minor revision number corresponds to an incremental improvement to the core architecture, possibly including new features.
Misc: Fence Synchronization
__threadfence_block()
waits until all global and shared memory accesses made by the calling thread prior to
__threadfence_block()are visible to all threads in the thread block
__threadfence()
waits until all global and shared memory accesses made by the calling thread prior to
__threadfence()are visible to:
- All threads in the thread block for shared memory accesses
- All threads in the device for global memory accesses
__threadfence_system()
waits until all global and shared memory accesses made by the calling thread prior to
__threadfence_system()are visible to:
- All threads in the thread block for shared memory accesses
- All threads in the device for global memory accesses
- Host threads for page-locked host memory accesses.
- (only supported by devices of compute capability 2.x.)
Misc: Atomics
An atomic function performs a read-modify-write atomic operation a word
- 32-bit or 64-bit word
- Residing in global or shared memory