What are the differences between multicore and manycore processors?
- Similar in scaling trends:
- Increasing vector unit width
- Increasing numbers of cores per die
- Increasing bandwidth to off-chip memory
- Different in optimization points
- Multicore: Each core optimized for executing a single thread
- SIMD level parallelism
- Core level parallelism
- Memory hierarchy
- Manycore: Cores optimized for aggregate throughput, deemphasizing individual performance
What is instruction level parallelism? What is SIMD?
ILP: how many of the operations in a computer program can be performed simultaneously.
SIMD: computers with multiple processing elements that perform the same operation on multiple data points simultaneously. There are simultaneous (parallel) computations, but only a single process (instruction) at a given moment. Thus, such machines exploit data level parallelism, but not concurrency
- Advantages:
- Power-efficient way to improve instruction throughput
- Exploitable in many compute-intensive applications
Why SIMD?
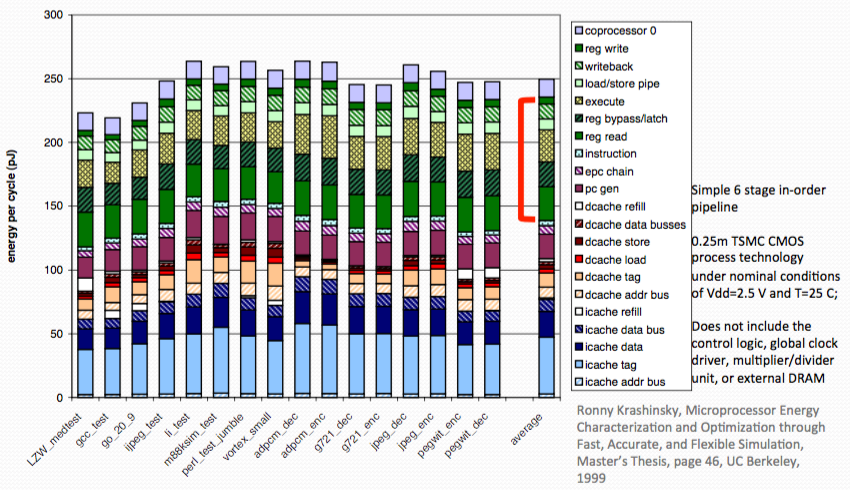
Lots of power are used for putting the instruction into instruction pip line. Only one third of energy are used for computation.
SIMD philosophy: by widening the pieces of data that's being processed on by the instructions, at the same time. We can amortize the cost of loading the data from RAM, and the cost of directing the instructions to the proper locations. Amortize those energy consumption, and silicon use. And dedicated more resources, more selection and more energy at one time to the computation of data.
How to use SIMD? Example: Vectorization
- GCC: Enable by options such as:
- -free-vectorize
- -msse2
- -ffast-math
- -fassociative-math
- Also enabled by default with “-O3”
What is is Simultaneous Multithreading (SMT):
- when more than one thread of instructions are available, we can gain power-efficiency by increasing processor pipeline utilization.
- May trigger conflicts in shared cache during execution
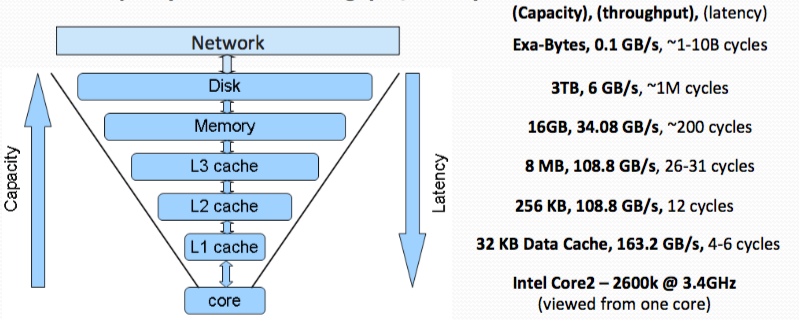
What are the three metrics for a memory hierarchy?
Physical properties of wires and transistors determines trade-off between cache capacity and access throughput/latency

Three metrics:
- Capacity: Size, e.g. number of bytes of data
- Latency: From start to finish, in units of time, e.g. CPU clock
- Cycles Throughput: Tasks accomplished per unit time, e.g. GB/s
- Trend: Capacity increase, latency increase, throughput decrease.
- Term Definition:
- Hit: Data is available in the level
- Miss: Data is missing from the level
Compulsory misses: caused by the first referenceCapacity misses: due to the finite size of the memory hierarchyConflict misses: due to policy of replacement, potenJally avoidableWriting fast code => get data from the fastest
(closest) level
What are the different system granularities? 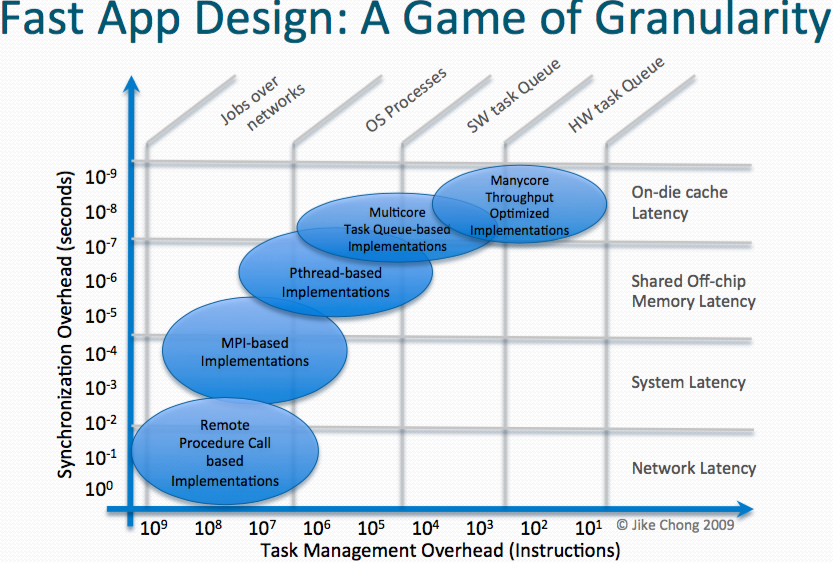
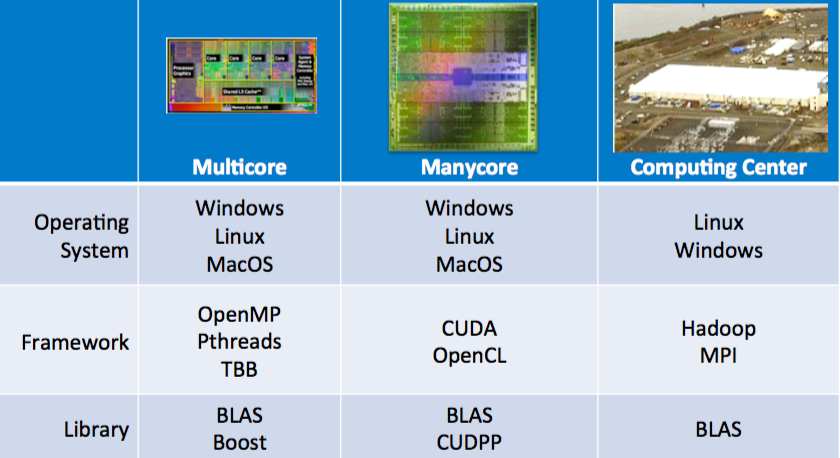
How is this relevant to writing fast code?