HBase
Apache HBase is an open-source version of Google's BigTable distributed storage system and is supported by the Apache Software Foundation. HBase is designed to accommodate a lot more data than traditional RDBMSs were. It provides the means to store and efficiently scan large swaths of data.
- HBase is a database that provides real-time, random read and write access to tables meant to store billions of rows and millions of columns.
- It is designed to run on a cluster of commodity servers and to automatically scale as more servers are added, while retaining the same performance.
- It is fault tolerant precisely because data is divided across servers in the cluster and stored in a redundant file system such as the Hadoop Distributed File System (HDFS).
- When (not if) servers fail, your data is safe, and the data is automatically re-balanced over the remaining servers until replacements are online.
- HBase is a strongly consistent data store; changes you make are immediately visible to all other clients.
HBase can be described as a key-value store with automatic data versioning.
You can CRUD (create, read, update, and delete) data just as you would expect.
- You can also perform scans of HBase table rows, which are always stored in HBase tables in ascending sort order.
- When you scan through HBase tables, rows are always returned in order by row key.
- Each row consists of a unique, sorted row key (think primary key in RDBMS terms) and an arbitrary number of columns,
- each column residing in a column family and having one or more versioned values.
- Values are simply byte arrays, and it's up to the application to transform these byte arrays as necessary to display and store them.
BigTable
- BigTable is a distributed, scalable, high-performance, versioned database.
- BigTable's infrastructure is designed to store billions of rows and columns of data in loosely defined tables.
- Just as traditional RDBMSs are designed to run on top of a local filesystem, HBase is designed to work on top of the Hadoop Distributed File System (HDFS).
- HDFS is a distributed file system that stores files as replicated blocks across multiple servers.
- HDFS lends a scalable and reliable file system back end to HBase.
HBase Structure
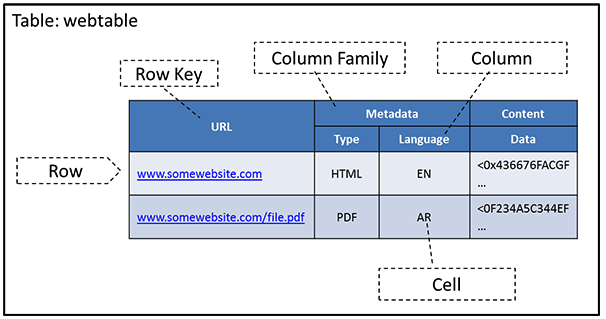
- A row in HBase is referenced using a row key which is raw byte array, which can be considered to be the primary key of the table in an RDBMS.
- The primary key of the table has to be unique and hence references one and only one row.
- HBase automatically sorts table rows by row key when it stores them. By default, this sort is byte ordered.
- As shown in the above figure, each key consists of the following parts: rowkey, column_family, column and timestamp. Thus the mapping becomes: (rowkey, column family, column, timestamp) -> value.
- Rowkey and value are simply bytes, so anything that could be serialized into bytes can be stored into a cell.
These cells in HBase are sorted lexicographically by rowkey which is a very important property as it allows for quick searching.
- Data are first sorted by row key, then by column family, then by family members, and finally by timestamp (so the latest values appear first).
Columns in HBase have a column name, which can be used to refer to a column.
- Columns can be further grouped into column families.
- All column family members have a common prefix, so, in the above figure, the columns Metadata:Type and Metadata:Language are both members of the Metadata column family, whereas Content:Data belongs to the Content family.
- By default, the colon character (:) delimits the column prefix from the family member.
- The column family prefix must be composed of printable characters. The qualifying tail can be made of any arbitrary bytes.
HBase Operations
HBase has four primary operations on the data model: Get, Put, Scan, and Delete.
- By default, Get, Scan, and Delete operations on an HBase table are performed on data that have the latest version.
- Each operation can be targeted to an explicit version number as well.
- A
Getoperation returns all of the cells for a specified row, which are pointed to by a row key.GetandScanoperations always return data in sorted order.
- A
Putoperation can either add new rows to the table when used with a new key or update a row if the key already exists. Scan is an operation that iterates over multiple rows based on some condition, such as a row key value or a column attribute.- A
Putoperation always creates a new version of the data that are put into HBase.
- A
- A
Deleteoperation removes a row from a table.- By default,
Deleteoperations delete an entire row but can also be used to delete specific versions of data in a row.
- By default,
HBase is Column-oriented
- HBase is a column-oriented data store, meaning it stores data by columns rather than by rows.
- This makes certain data access patterns much less expensive than with traditional row-oriented relational database systems.
- In HBase if there is no data for a given column family, it simply does not store anything at all; contrast this with a relational database which must store null values explicitly.
- In addition, when retrieving data in HBase, you should only ask for the specific column families you need; because there can literally be millions of columns in a given row, you need to make sure you ask only for the data you actually need.
- An important characteristic of HBase is that you define column families, but then you can add any number of columns within that family, identified by the column qualifier.
- HBase is optimized to store columns together on disk, allowing for more efficient storage since columns that don't exist don't take up any space
- unlike in a RDBMS where
nullvalues must actually be stored.
- unlike in a RDBMS where
- Rows are defined by columns they contain; if there are no columns then the row, logically, does not exist.
What Is The Difference Between HBase and Hadoop/HDFS?
- HDFS is a distributed file system that is well suited for the storage of large files. It's documentation states that it is not, however, a general purpose file system, and does not provide fast individual record lookups in files.
- HBase, on the other hand, is built on top of HDFS and provides fast record lookups (and updates) for large tables. This can sometimes be a point of conceptual confusion.
HBase internally puts your data in indexed "StoreFiles" that exist on HDFS for high-speed lookups.
References
- HBase web site, http://hbase.apache.org/
- HBase wiki, http://wiki.apache.org/hadoop/Hbase
- HBase Reference Guide http://hbase.apache.org/book/book.html
- HBase: The Definitive Guide, http://bit.ly/hbase-definitive-guide
- Google Bigtable Paper, http://labs.google.com/papers/bigtable.html
- Hadoop web site, http://hadoop.apache.org/
- Hadoop: The Definitive Guide, http://bit.ly/hadoop-definitive-guide
- Fallacies of Distributed Computing, http://en.wikipedia.org/wiki/Fallacies_of_Distributed_Computing
- HBase lightning talk slides, http://www.slideshare.net/scottleber/hbase-lightningtalk
- Sample code, https://github.com/sleberknight/basic-hbase-examples