HBase Architecture, explained from Site
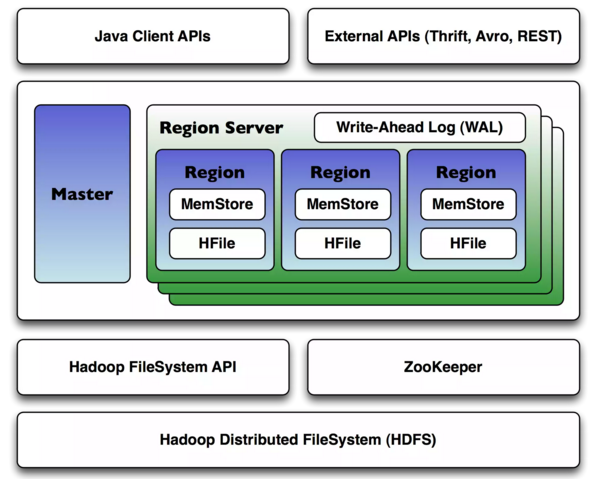
Master-Slave Architecture
- A single HBase master node and multiple slave nodes (region servers).
- It is possible to run HBase in a multiple master setup, in which there is a single active master.)
- HBase tables are partitioned into multiple regions
- Each region storing a range of the table's rows
- Multiple regions are assigned by the master to a region server.
- Each RegionServer can serve several Regions, but one Region can only be served by a specific RegionServer.
- Even though an HBase Region can only be served by one RegionServer, this does not mean the data of that Region can only exist in one RegionServer.
- In fact, due to data replication of HDFS, there will be some exact copies of the data of each Region on another RegionServer.
Region
- An HBase Region is a subset of an HBase table, but has a continuous range of sorted rowkeys.
- Regions contain an in-memory data store (MemStore) and a persistent data store (HFile)
- Each region holds a specific range of row keys, and when a region exceeds a configurable size, HBase automatically splits the region into two child regions, which is the key to scaling HBase.
- As a table grows, more and more regions are created and spread across the entire cluster.
- When clients request a specific row key or scan a range of row keys, HBase tells them the regions on which those keys exist, and the clients then communicate directly with the region servers where those regions exist.
- This design minimizes the number of disk seeks required to find any given row, and optimizes HBase toward disk transfer when returning data.
- This is in contrast to relational databases, which might need to do a large number of disk seeks before transferring data from disk, even with indexes.
Write-Ahead Log (WAL)
- All regions on a region server share a reference to the write-ahead log (WAL) which is used to store new data that hasn't yet been persisted to permanent storage and to recover from region server crashes.
Zookeeper
- HBase utilizes ZooKeeper (a distributed coordination service) to manage region assignments to region servers, and to recover from region server crashes by loading the crashed region server's regions onto other functioning region servers.
- For example, it handles master selection (choosing one of the nodes to be the master node), the lookup for the -ROOT- catalog table, and node registration (when new regionservers are added).
- The master node that is chosen by ZooKeeper handles such functions as region allocation, failover, and load balancing.
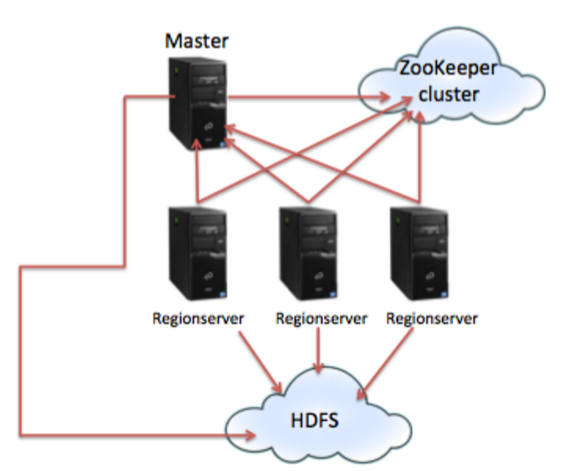
HDFS
- The HDFS component is the Hadoop Distributed Filesystem
- a distributed, fault-tolerant and scalable filesystem which guards against data loss by dividing files into blocks and spreading them across the cluster;
- It is where HBase actually stores data.
- Strictly speaking the persistent storage can be anything that implements the Hadoop FileSystem API, but usually HBase is deployed onto Hadoop clusters running HDFS.
- In fact, when you first download and install HBase on a single machine, it uses the local filesystem until you change the configuration!
API
- Clients interact with HBase via one of several available APIs, including a native Java API as well as a REST-based interface and several RPC interfaces (Apache Thrift, Apache Avro).
- You can also use DSLs to HBase from Groovy, Jython, and Scala.