Hadoop
Overview
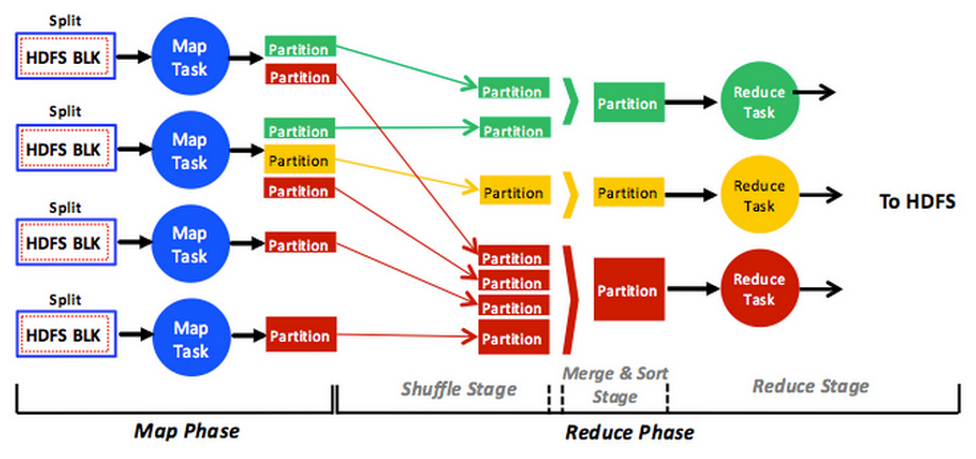
A MapReduce job usually
- splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner.
- The framework sorts the outputs of the maps, which are then input to the reduce tasks.
- Typically both the input and the output of the job are stored in a file-system.
- The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
- Typically the compute nodes and the storage nodes are the same
- that is, the MapReduce framework and the Hadoop Distributed File System (see HDFS Architecture Guide) are running on the same set of nodes.
- This configuration allows the framework to effectively schedule tasks on the nodes where data is already present, resulting in very high aggregate bandwidth across the cluster.
The MapReduce framework consists of
- a single master ResourceManager, one slave NodeManager per cluster-node, and MRAppMaster per application.
- Minimally, applications specify the input/output locations and supply map and reduce functions via implementations of appropriate interfaces and/or abstract-classes.
- The Hadoop job client then submits the job (jar/executable etc.) and configuration to the ResourceManager which then assumes the responsibility of distributing the software/configuration to the slaves, scheduling tasks and monitoring them, providing status and diagnostic information to the job-client.
Hadoop Streamingis a utility which allows users to create and run jobs with any executables (e.g. shell utilities) as the mapper and/or the reducer.Hadoop Pipesis a SWIG-compatible C++ API to implement MapReduce applications (non JNI™ based).
Inputs and Outputs
- The
keyandvalueclasses have to be serializable by the framework and hence need to implement theWritableinterface. - Additionally, the
keyclasses have to implement theWritableComparableinterface to facilitate sorting by the framework.
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)