What are the three ways to improve execution throughput?
- SoA vs AoS
SoA: Structure of Array:
[xxx] [yyy] or xxxyyyzzz [zzz]AoS: Array of Structure:
[xyz][xyz][xyz]When to use SOA vs AOS?
Which one is better depends on
- What is the computation?
- What is the optimization goal?
SOA
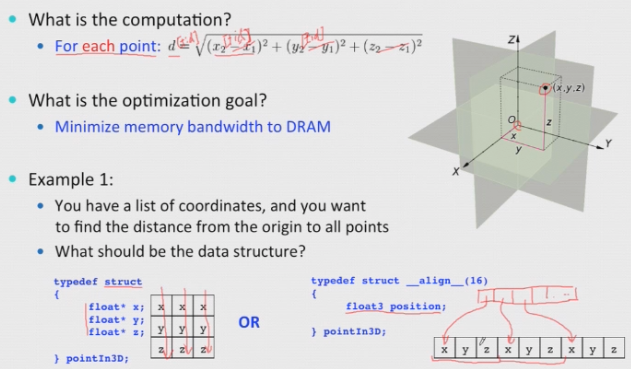
AOS
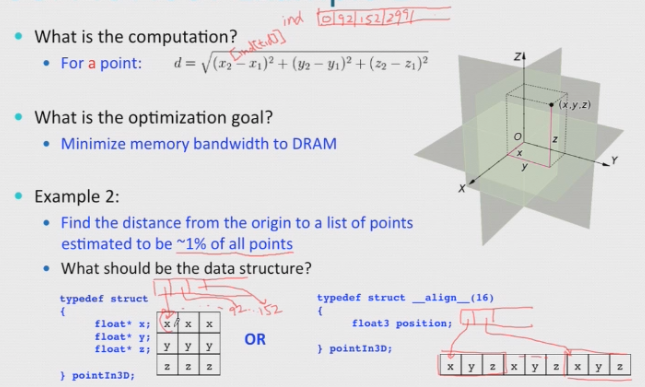
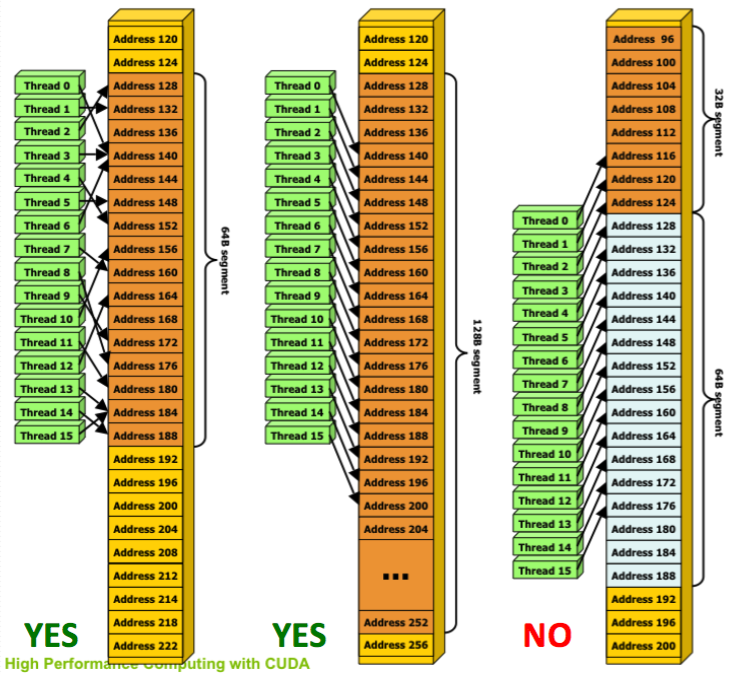
What is memory Coalescing? When to use it? Why is it important?
- Memory coalescing
- Hardware Constraint: DRAM is accessed in “segments” of 32B/64B/128B
- Unused data loaded in a “segment” still takes up valuable bandwidth
- Rules for maximizing DRAM memory bandwidth:
- Possible bus transaction sizes: 32B, 64B, or 128B
- Memory segment must be aligned: First address = multiple of segment size
- Hardware coalescing for each half-warp: 16-word wide
- Find the memory segment that contains the address requested by the active thread with the lowest thread ID.
- 32 bytes for 1-byte words
- 64 bytes for 2-byte words
- 128 bytes for 4-, 8- and 16-byte words.
What is shared memory? How to use it?
Take advantage of 9x faster memory bandwidth
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
//or
extern __shared__ char sharedMemory[];
// In host code
mykernel <<< nBlks, nThds, shmemByteSize >>> (a, objects);
Techniques: double buffering, load the shared memory in a pipeline fashion.
- When load next tile from global memory, don't use synchronize threads, so that it might computer current tile at the same time.

What is memory bank conflict? How to work around it?
- Shared memory has 32 banks
- Organized such that successive 32-bit words are assigned to successive banks
Each bank has a bandwidth of 32 bits per two clock cycles (2 cycle latency) A bank conflict occurs if two or more threads access any bytes within different 32-bit words belonging to the same bank

Trick: Padding to reduce the memory conflict
- Choose R to be some prime like 33

What is branch divergence?
- Choose R to be some prime like 33
- It works well when all threads within a warp follow the same control flow path when working their data.
- For example, for an if–then–else construct, the execution works well when either all threads execute the then part or all execute the else part. When threads within a warp take different control flow paths, the simple execution style no longer works well. In our if–then–else example, when some threads execute the then part and others execute the else part, the SIMT execution style no longer works well. In such situations, the execution of the warp will require multiple passes through these divergent paths.
- When threads in the same warp follow different paths of control flow, we say that these threads diverge in their execution.
How to optimize for instruction mix?
What is occupancy? How to model/measure it?
How to use the code profiler with CUDA?