HDFS
HDFS is an open-source clone of GFS. HDFS is designed to be a distributed, scalable, fault-tolerant file system that primarily caters to the needs of the MapReduce programming model.
HDFS is typically accessed via HDFS clients or by using application programming interface (API) calls from the Hadoop libraries. However, the development of a File system in User SpacE (FUSE) driver for (HDFS) allows it to be mounted as a virtual device in UNIX-like operating systems.
Design Goals
- A single, common, cluster-wide namespace
- Ability to store large files (e.g. terabytes or petabytes)
- Support for the MapReduce programming model
- Streaming data access for write-once, read-many data access patterns
High availability using commodity hardware
This design choice in HDFS was made because some of the most common MapReduce workloads follow the write once, read many data-access pattern. MapReduce is a restricted computational model with predefined stages, and outputs of reducers in MapReduce write independent files to HDFS as output. HDFS focuses on simultaneous, fast read accesses for multiple clients at a time.
Architecture
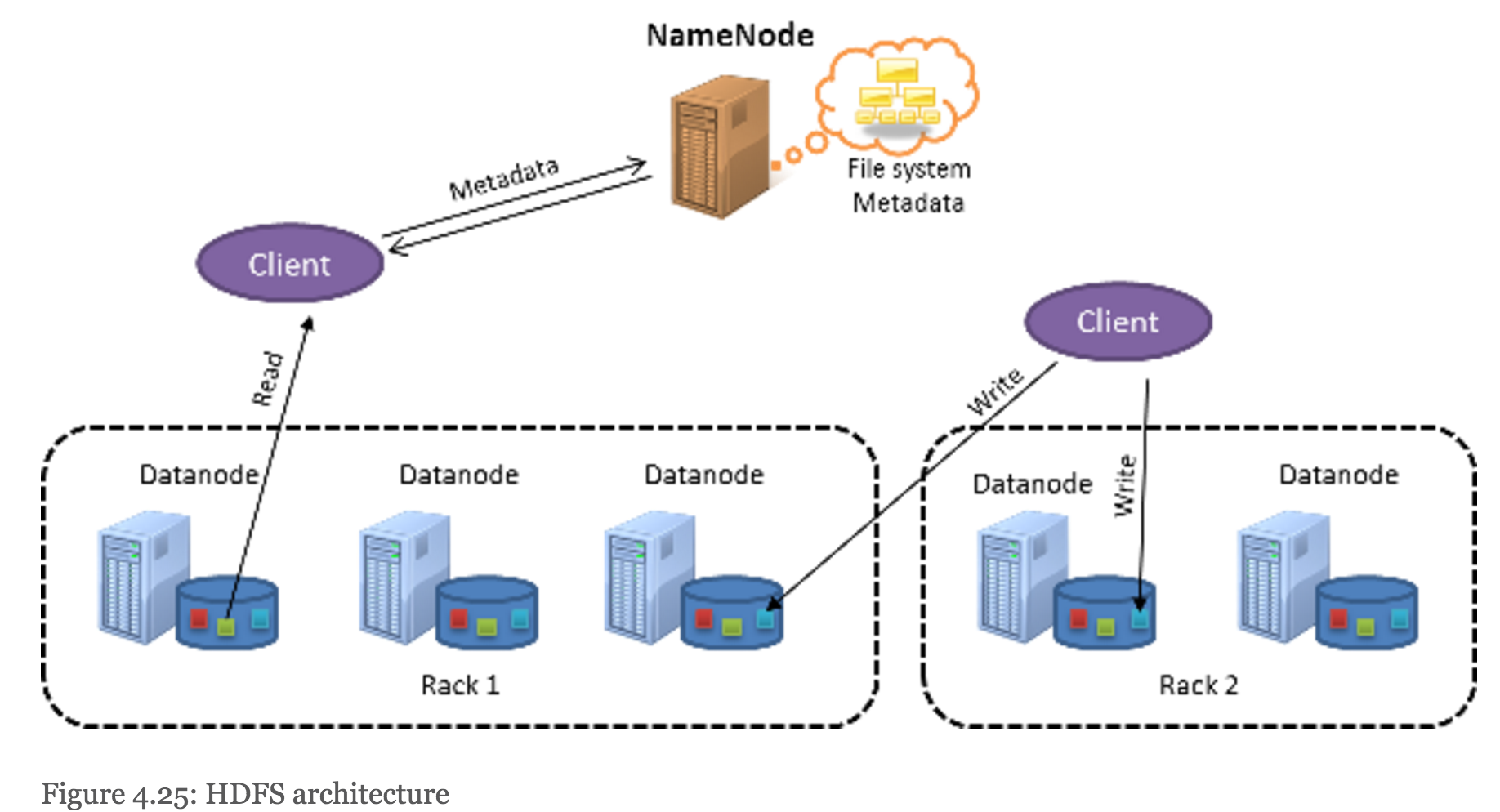
HDFS follows a master-slave design. The master node is called the NameNode. The NameNode handles the metadata management for the entire cluster and maintains a single namespace for all the files stored on HDFS. The slave nodes are known as DataNodes. The DataNodes store the actual data blocks on the local file system within each node.
- Files in HDFS are split into blocks (also called chunks), with a default size of 128MB each.
- HDFS uses large block sizes because it is designed to store extremely large files in a manner that is efficient to process with MapReduce jobs.
- HDFS allows block sizes to be specified on a per-file basis, so users can tune the block size to achieve the level of parallelism they desire.
- data blocks are replicated across nodes to provide data redundancy.
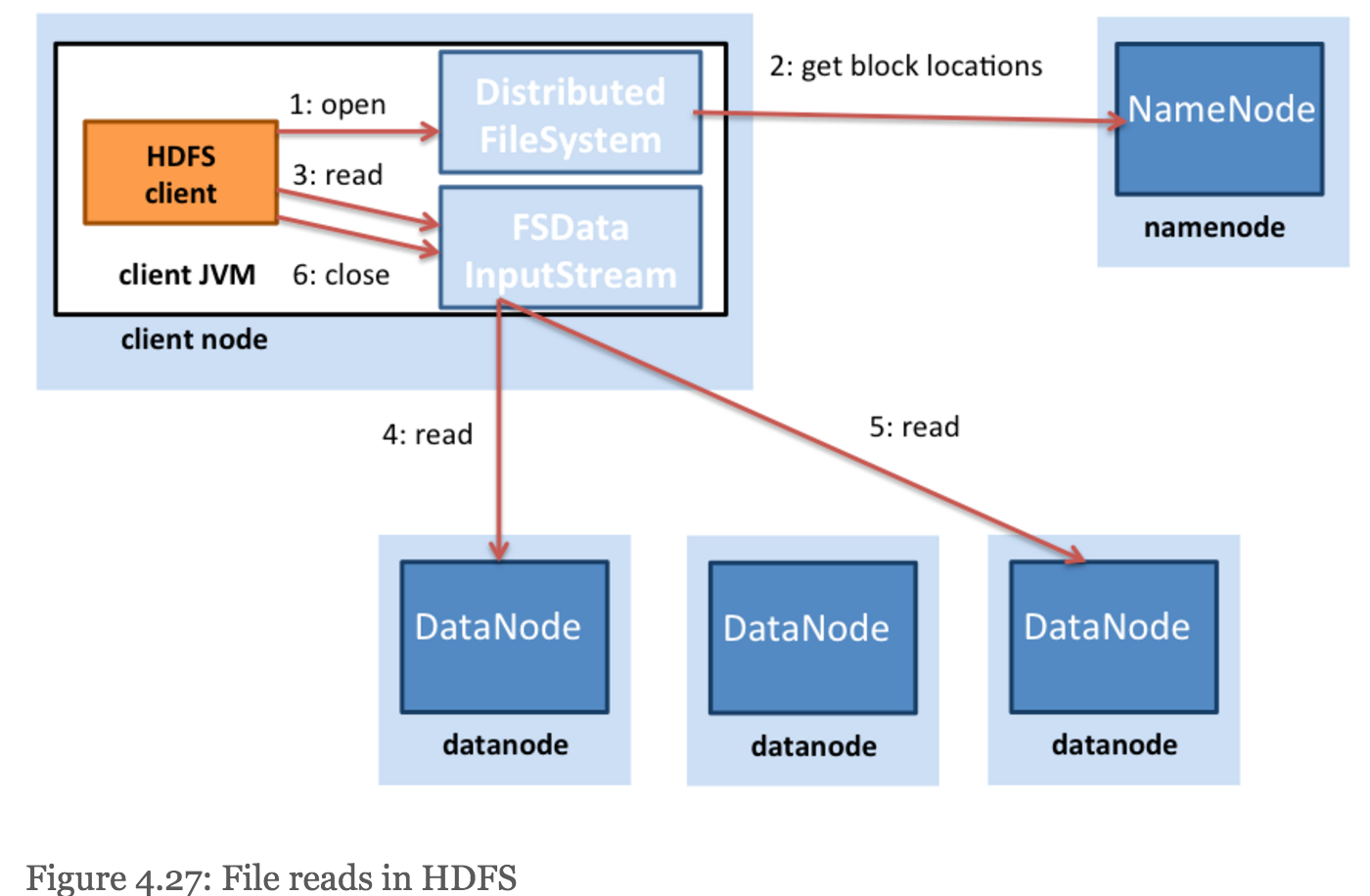
- NameNode actually finds the closest block to the client when providing the location of a particular block.
- clients contact the DataNode directly to retrieve data.
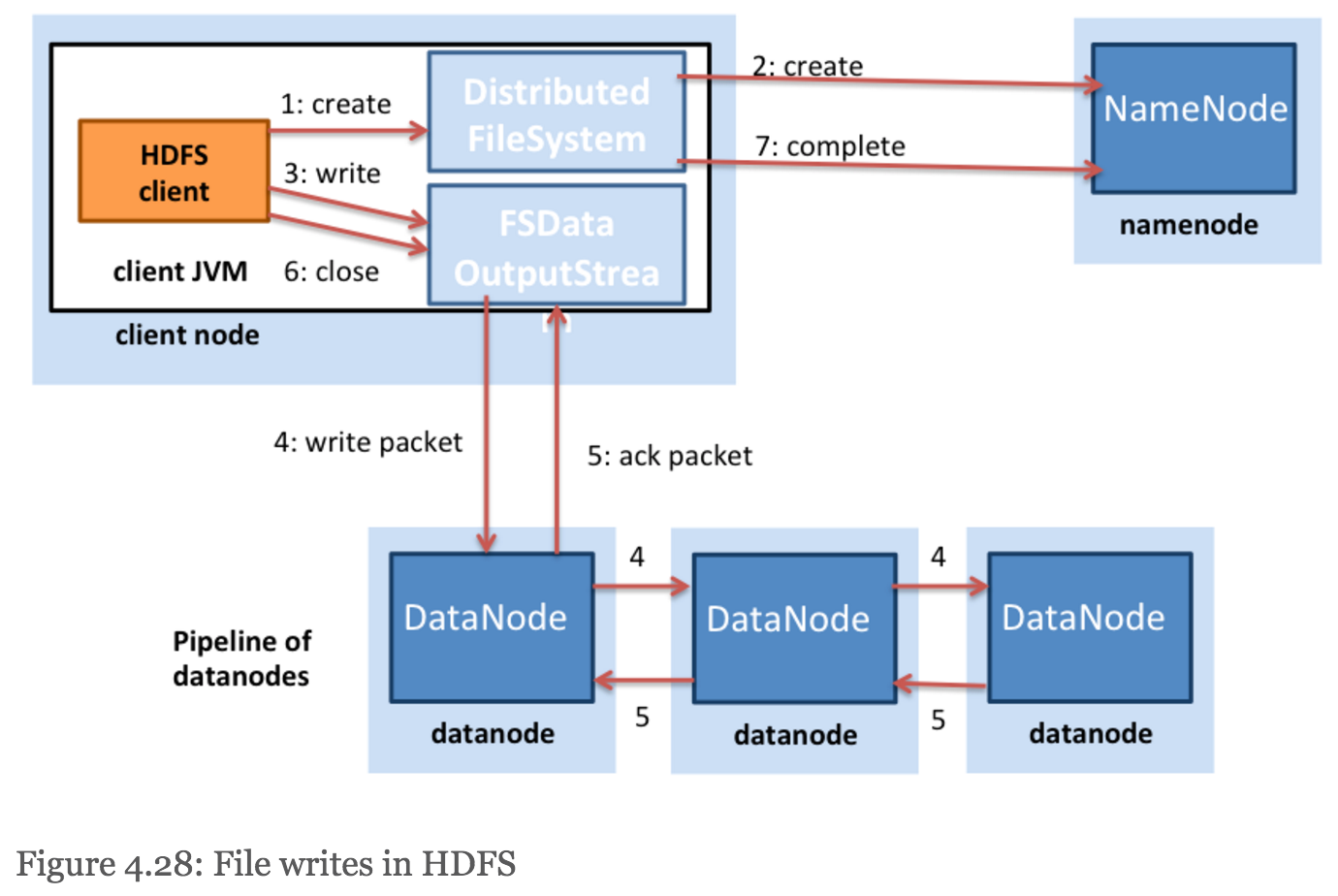
- HDFS does not acknowledge a write to the client (step 5 in Figure 4.28) until all the replicas for that file have been written by the DataNodes.
- system tries to avoid placing too many replicas on the same rack.
- In case a client process is not running in the HDFS cluster, a node is chosen at random. The second replica is written to a node that is on a different rack from the first (off rack). The third replica of the block is then written to another random node on the same rack as the second.